用jupyter写程序时小心意外的全局变量
这周写作业, 用jupyter时遇坑一枚, 导致我改了作业10次以后才全对通过.
 而且这个坑与我当前的编程习惯有关. 有必要记录下来, 以免未来再犯.
而且这个坑与我当前的编程习惯有关. 有必要记录下来, 以免未来再犯.
这周写作业, 用jupyter时遇坑一枚, 导致我改了作业10次以后才全对通过.
而且这个坑与我当前的编程习惯有关. 有必要记录下来, 以免未来再犯.
Convert NOAA weahter data file ".dly" to Pandas DataFrame
Follow this instruction https://www1.ncdc.noaa.gov/pub/data/ghcn/daily/readme.txt
Get data from ftp://ftp.ncdc.noaa.gov/pub/data/ghcn/daily
本文使用cc-by 4.0 协议
安全带上做一护套, 用反光布绣上 ”唵嘛呢叭咪吽”
系好安全带时有六字真言胸前护体, 注意切不可置于背后或者放在一边.
发明是要提供社会有益效果的.
但是世上居然有类似安全带插头这种邪恶的发明, 用来欺骗汽车的安检系统, 在不系安全带时避免警报器响. 这是在谋财+害命.
很遗憾, 据我观察如果一辆车上摆着佛像, 后视镜上挂着佛像/十字架/毛主席像, 那么安全带扣位置上高概率出现这种安全带插头. 喂! 你们的神已经派遣Nils Bohlin在1958年发明三点式安全带来保护大家了, 为什么要欺骗他.
(写于2012年3月)
学位和能力是两码事,顶多有点相关性,相关系数还不是很高。
学位和学识也是两码事,即使读到头,不继续学习的话,马上知识就陈旧了。所谓逆水行舟,不进则退。其实这个比喻是有欠缺的,一般会认为水流速度是常数,但是请设想一下水流的速度是指数函数呢?
看到starnight做
蛤, 读过算什么, 我还写过呢. 来两篇以前的:
(写于2012年) 学习是个持续过程。
逆水行舟不进则退。逆水行舟不进则退还是不确切的,因为通常水流速度是常数。但是考虑人类的知识进展的速度,却可能是指数函数。也就是说,逆水行舟,水的速度是指数变化,这事想起来非常可怕。也许你现在每周需要看两篇文献能够保持在前沿的位置,18个月以后,是每周四篇,3年以后是每周8篇。。。20年以后,我们就必须用Matrix的upload功能来学习了。当然现在事情还没有那么夸张,不同领域的倍增时间并不相同。
我觉得自学,或者说自己对自己的继续教育是需要持续进行的。
世界银行数据清洗工具.
世界银行有个开放的数据库http://data.worldbank.org 这个数据库很强大, 里面有各国各种经济数据. 我看了GDP, GDP年增长率, 税收, 税收占GDP百分比几个数据集, 发现里面的格式基本相同. 因此就可以统一清理数据了.
所以做了一个这样的简单清洗器. 两个函数:
在曼昆的_经济学原理_的第八章中, 讲解了税收与经济之间的关系. 当税率逐渐提高时, 税收的总额会先提高, 税率到达一定水平以后由于税收对经济的影响, 税收反而会下降. 这一变化过程称为拉伐曲线.
根据_经济学原理_中引用“The New York Times,November14.1996,p.D2.”的一篇文章中说, 在1996年之后, 乌克兰打算进行税收的改革, 大幅度减税, 并通过减税来刺激经济.
那么, 这个案例的结果是怎样的? 乌克兰是否按照计划进行了减税, 减税之后该国的经济是否发生了改善? 在这本书中并没有讲解.
本文通过世界银行中乌克兰以及周边前独联体国家的公开数据进行了初步的分析.
在上一篇"统计图整理"中, 展示了如何把一个具有浓郁乡土气息的bar
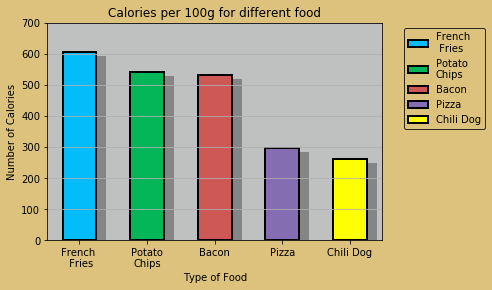 变成性冷淡的bar:
变成性冷淡的bar:
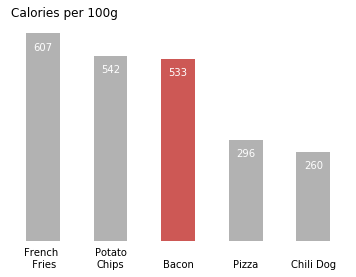
大家的反馈主要是对Remove lines到direct label的那一部分不认同. 也就是从去掉grid, 去掉座标轴, 到直接将数据标注到bar上.
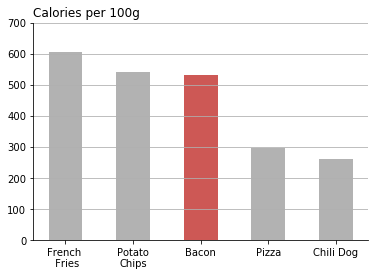
专业设计师如西乔都认为"觉得水平线还是应该保留,目前有些影响可读性", 其实我也有类似的感觉. 很可能这是大多数人的感觉.
在"统计图整理"一文中我说,
如果做乙方的话, 一定要花足够长的时间给甲方洗脑, 洗到less is more形成本能. 如果你省掉了什么时间, 一定会乘10花到工作时间上.
我只讲了目的, 没有讲解方法. 作为完整的课程, cousera这门课不仅仅讲解了如何作图, 实际上还悄悄演示了如何"洗脑".
最近正在学Applied Plotting, Charting & Data Representation in Python, 老师在第一周的课程中先讲了一遍统计图的审美, 其中有一段是展示如何将图中无用的部分清除, 所谓Dejunkify, 以强调显示主题. 感觉非常好. 完成第二周的作业后, 我应该是能够用matplotlib进行基本的画图了. 所以试着把这个例子重现一遍.
课程中的例子来自于Dark Horse
爱德华·图夫特(Edward Tufte)在他1983年经典的著作“量化信息的视觉显示”(The Visual Display of Quantitative Information) 一书中指出:“数据墨水(Data-ink)是图像中不可抹去的核心,是为了反映数字的变化而安排的不可或缺的印迹”
Edward Tufte introduced the concept of data-ink in his 1983 classic The Visual Display of Quantitative Information. In it he states "Data-ink is the non-erasable core of the graphic, the non-redundant ink arranged in response to variation in the numbers represented" (emphasis mine).
一个"好"的统计图, 应当是尽可能多的保留data ink, 尽可能少的chart junk. 这一段动画显示了如何把一个凌乱的统计图删减到只包含必要的"Data-ink"的过程.

接下来我试着用matplotlib重现这个过程, 也算是参照matplotlib cheat sheet 的一次练习.