机器学习的知识产权保护(1)--保护的难题
企业想保护的是什么
机器学习, 尤其是现今流行的深度学习, 主要是深度神经网络, 其中包含两个部分: 网络结构, 比如用了几个隐含层, 每个隐含层的神经元数量各自是多少, 激活函数用的是ReLU还是tanh还是其他, 卷积层是怎样的, 有没有层间直接的连接等等. 网络参数, 每个神经元都只是做$Z=W A +B $, A是上一层传来的值, 独立参与计算的就是W和B.
机器学习, 尤其是现今流行的深度学习, 主要是深度神经网络, 其中包含两个部分: 网络结构, 比如用了几个隐含层, 每个隐含层的神经元数量各自是多少, 激活函数用的是ReLU还是tanh还是其他, 卷积层是怎样的, 有没有层间直接的连接等等. 网络参数, 每个神经元都只是做$Z=W A +B $, A是上一层传来的值, 独立参与计算的就是W和B.
估计最近又要开始炒VR和近视了,需要尽快给各位投资人预防接种一下:
首先近视产生和进展的原理目前研究还没有足够清楚。
目前有实验证据的,“!延缓近视进展!”的方法只有足量的户外活动、角膜塑形镜和低浓度阿托品。注意只是控制进展,没有哪个敢说“治疗”近视。成年以后做手术可以治疗近视。
空气炮是一种常见的玩具, 利用空气脉冲释放出一个空气涡旋(air vortex), 这种air vortex可以在长距离内保持形状, 其内部的空气很少与外界空气交换, 而且投递的精度很高. 当air vortex遇到阻挡或者与另一个air vortex相撞时, vortex的结构破坏, 里面的空气释放出来.
于是可以用来将热空气或冷空气以特定形式进行长距离、高空间精度的投递。除了用作空调, 也可以用来投递气味, 还可以用来投递干净的空气.
优点是只需要对少量的空气进行加工就可以满足个人的要求. 不需要过滤整个屋子的PM2.5, 只需要过滤用户吸入的那一部分就可以了.
缺点是噪音, 我估计是因为噪音的问题导致这个技术一直没有出现在市场上.
这个发明, 想的时间晚了, 已经有很多相似的现有技术在先. 所以没有卖掉.
我是职业发明家, 从事发明的生产. 总会有一些卖不掉的发明, 有些是过于超前, 有些是不合时宜. . . . . .
有些是已经有人发明过了, 最后这类当然是最多的, 毕竟要和全世界几十亿人竞争, 谁知道是不是会有哪个以色列人偷偷地申请了一个发明放着.
接下来, 我会选择一些确定不能卖掉的发明展示. 如果是没有新颖性的, 我也尽量给出现有技术的文献.
大胆假设, 小心求证. 说的是启发系统和验证系统. 启发系统获得可能解, 验证系统去测试所有可能解中哪些是正确的.
先展示几张效果图:

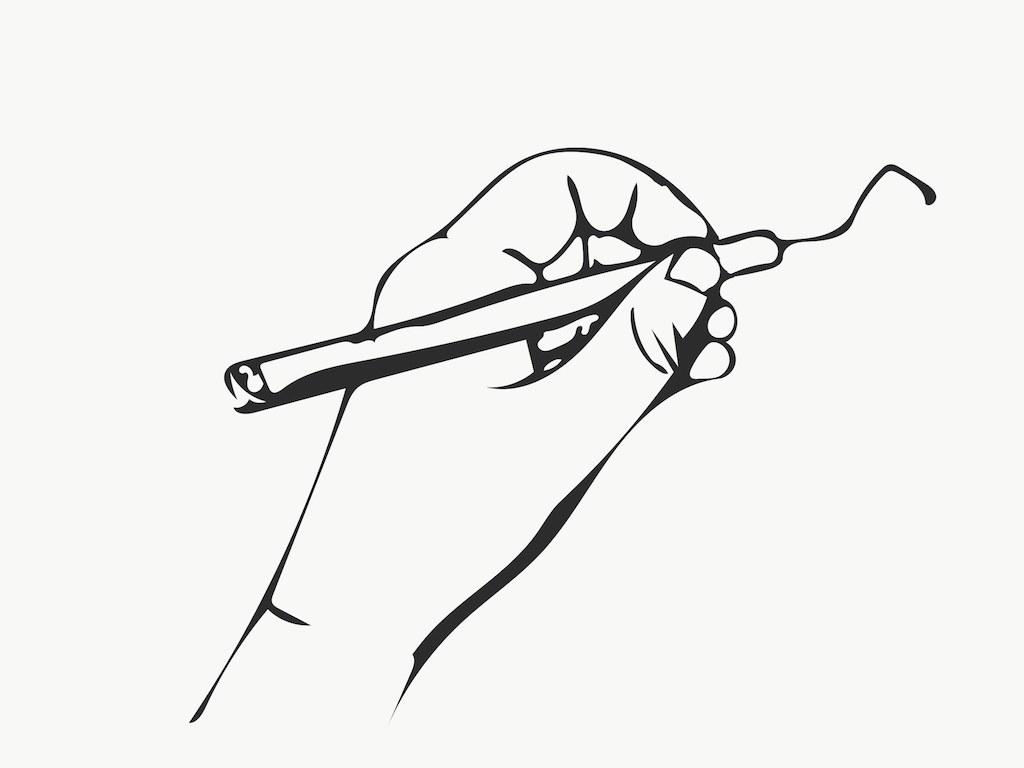
需要的的APP 在iOS上
adobe draw
在android上
注意在android上,adobe draw和gather之间并没有非常好的衔接,还是需要同步到adobe的库中以后才能调用,而adobe服务器从国内访问的速度又很慢。
但,我有iPad,哪管android上的好用不好用。反正iPad上挺好用的。

1 拍照 对常见场景拍照,比如手持器械的照片,或者需要讲解的场景。
尽量在白色背景上照相,比如白色桌面或者是白纸上。
物体和手最好稍微离开桌面,以免留下明显的阴影。

2 在adobe draw中新建图画,在图层中添加image layer,导入刚刚拍摄的场景照片。
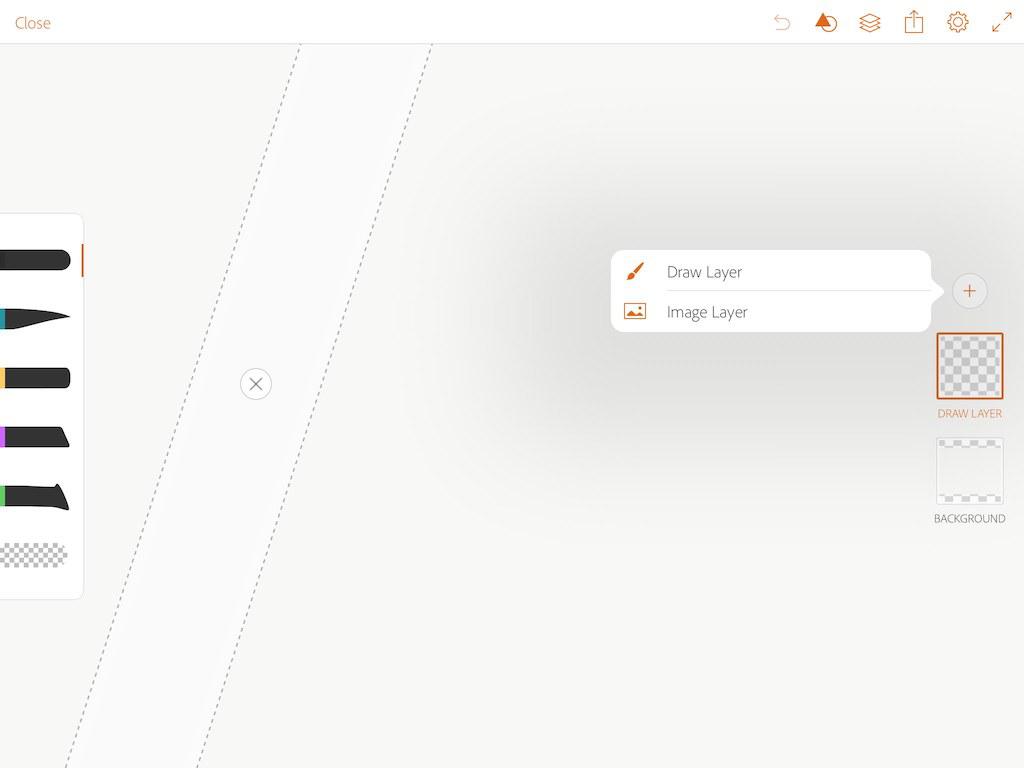
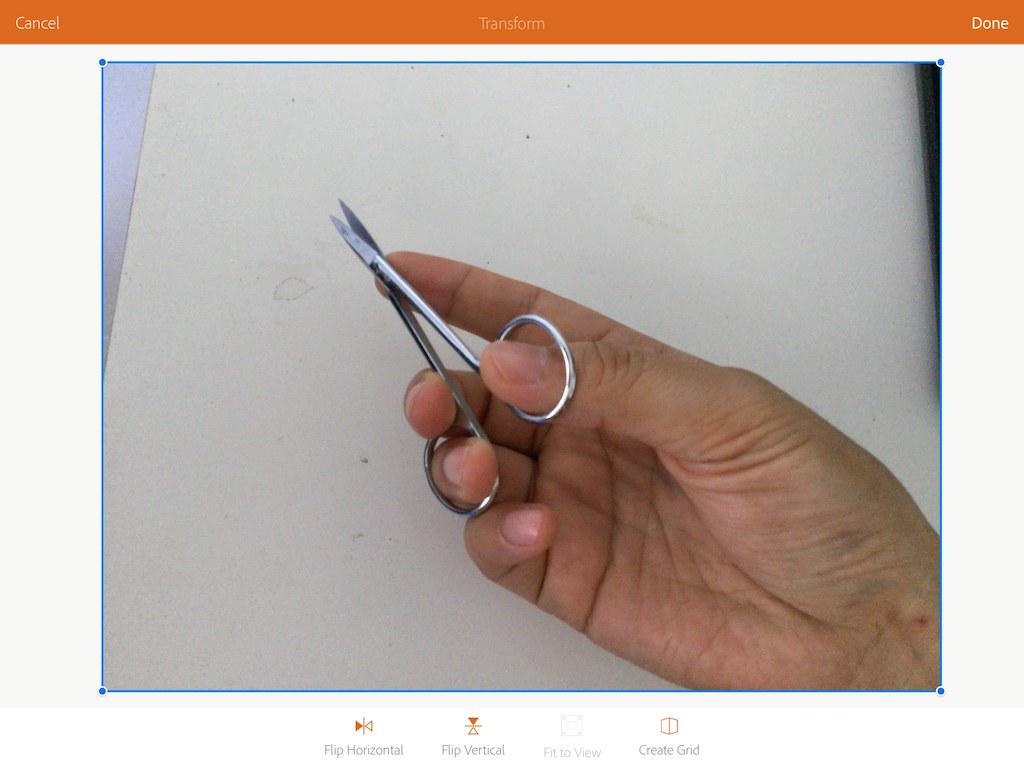
3 添加draw layer图层后,点击打开shape,然后点击“+”号,会自动切换至adobe capture。
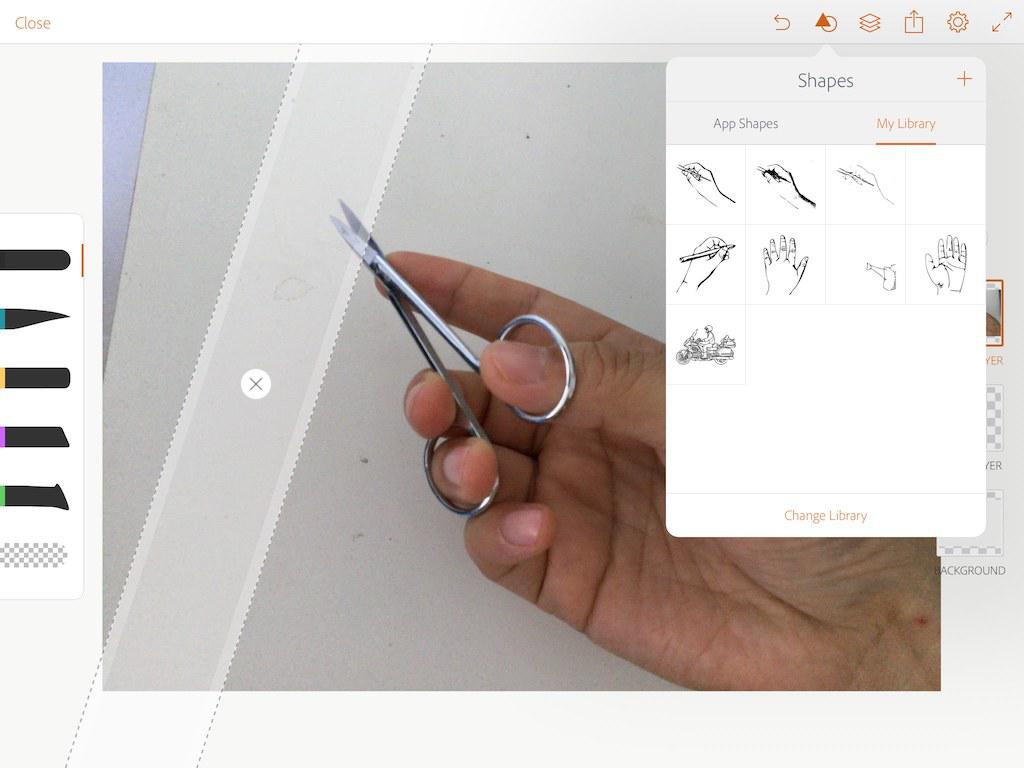
在adobe capture中从camera roll中导入照片
4 调整滑动条,使采集的图像仅仅保留边缘的线条,
采集后清除多余的线条和杂点,
在preview中,smooth选项推荐处于OFF关闭状态
之后save & return to adobe draw(屏幕顶部橙色条)

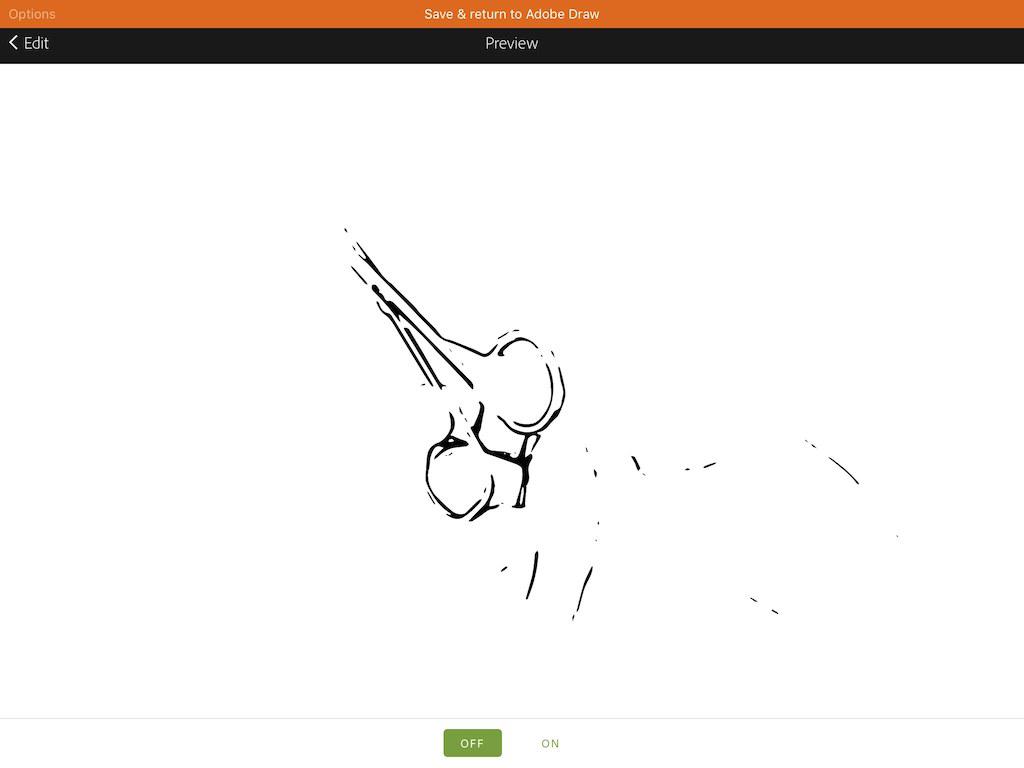
5 在新建的draw layer图层中,小心地用双手指调整shape的大小和位置,直到与底部的照片相吻合,然后双击屏幕,shape印章盖下。
本层暂且称为浅色层
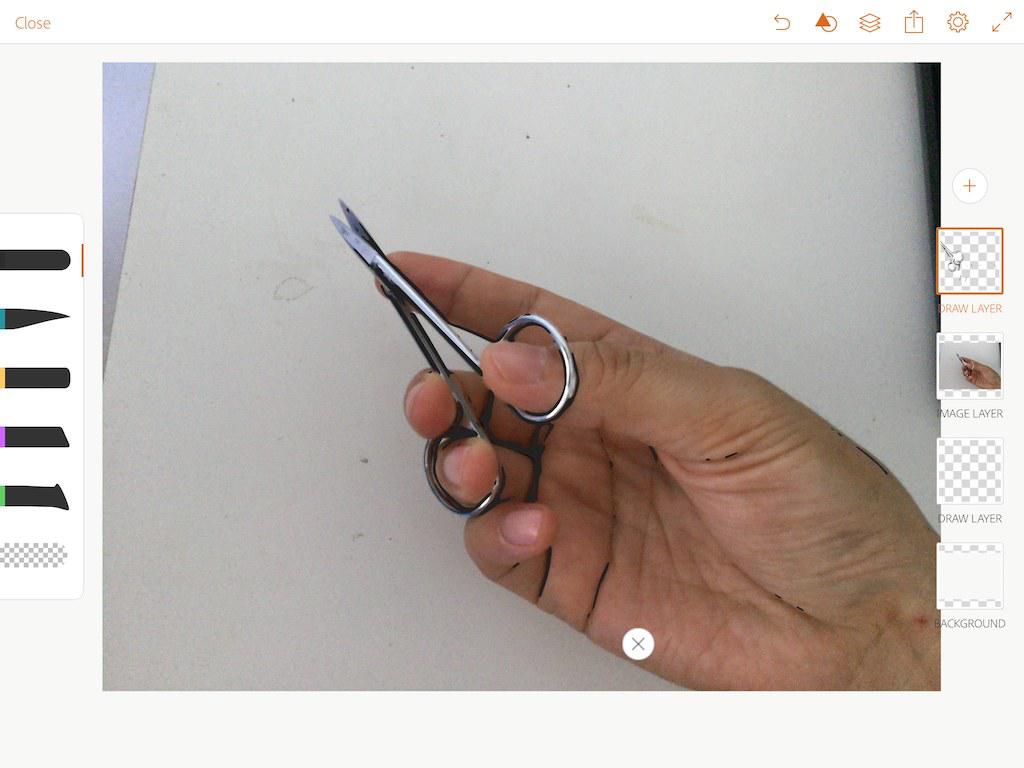
6 再次重复:
新建draw layer图层,
点击shape菜单,点击+,
在adobe capture中导入照片。
本次调整滑动条,向较深颜色方向移动,记录更多的细节。
然后capture
save & return
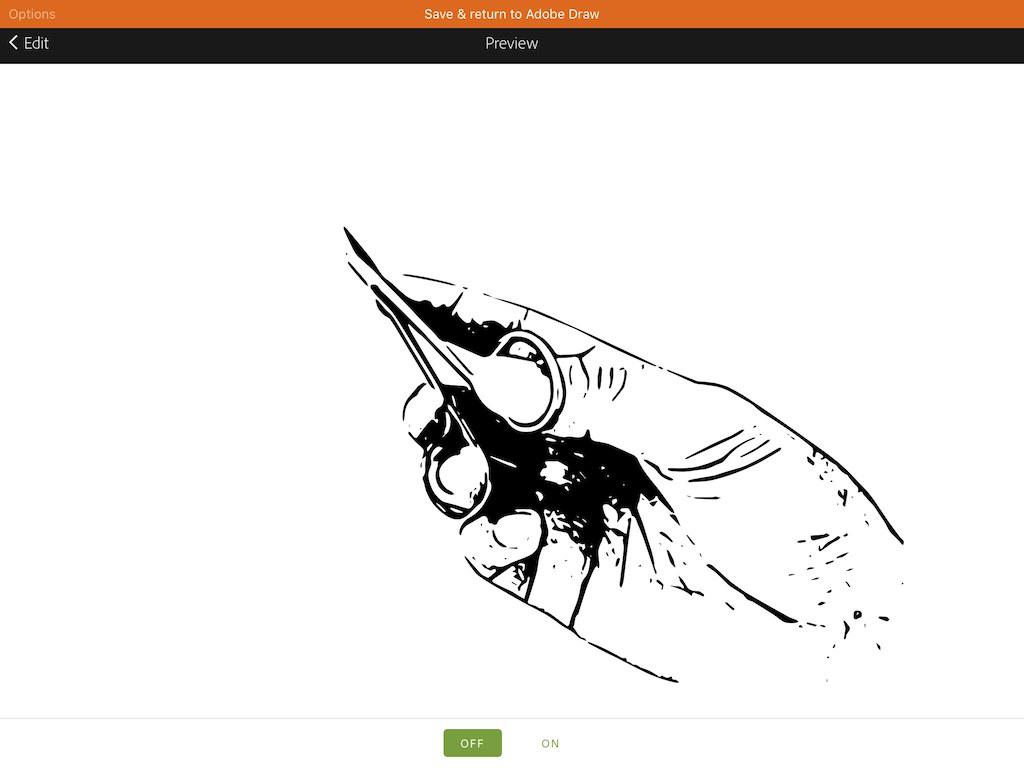
7 在adobe draw中新建的draw layer图层,
调整好shape的位置后,双击屏幕,shape印章盖下
本层暂且称为深色层

8 新建draw layer图层,
用笔按照照片的提示描绘缺少边缘的细节,比如剪子尖端。不需要非常精细地描绘,
用笔填充无用的空洞
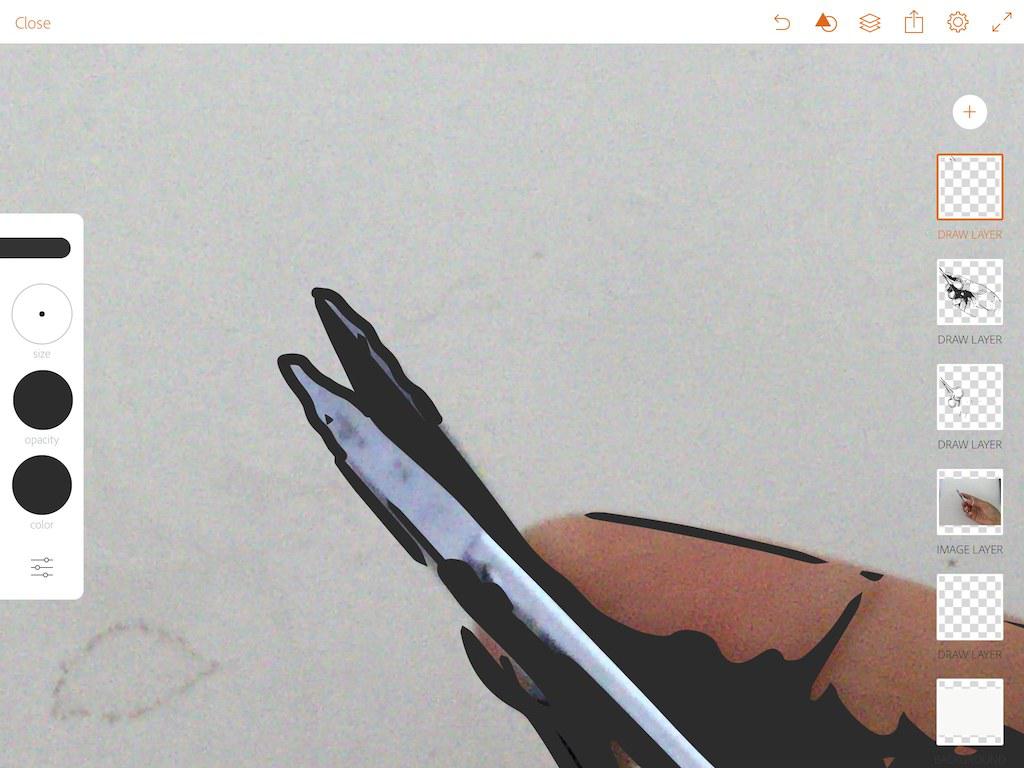
9 在深色图层中
用橡皮擦擦去多余的点、连成片的黑色区域,并适当使用笔补充边缘线条。
完成后,将照片层隐藏,底色层隐藏,然后导出为图片,存入camera roll。
10 新建draw layer图层,隐藏其余所有图层,
点击shape菜单中的“+”号,进入adobe capture,导入刚刚存入camera roll的线条图。
稍微清理后,在preview中注意将smooth的开关打开至ON,
完成后save & return to adobe draw
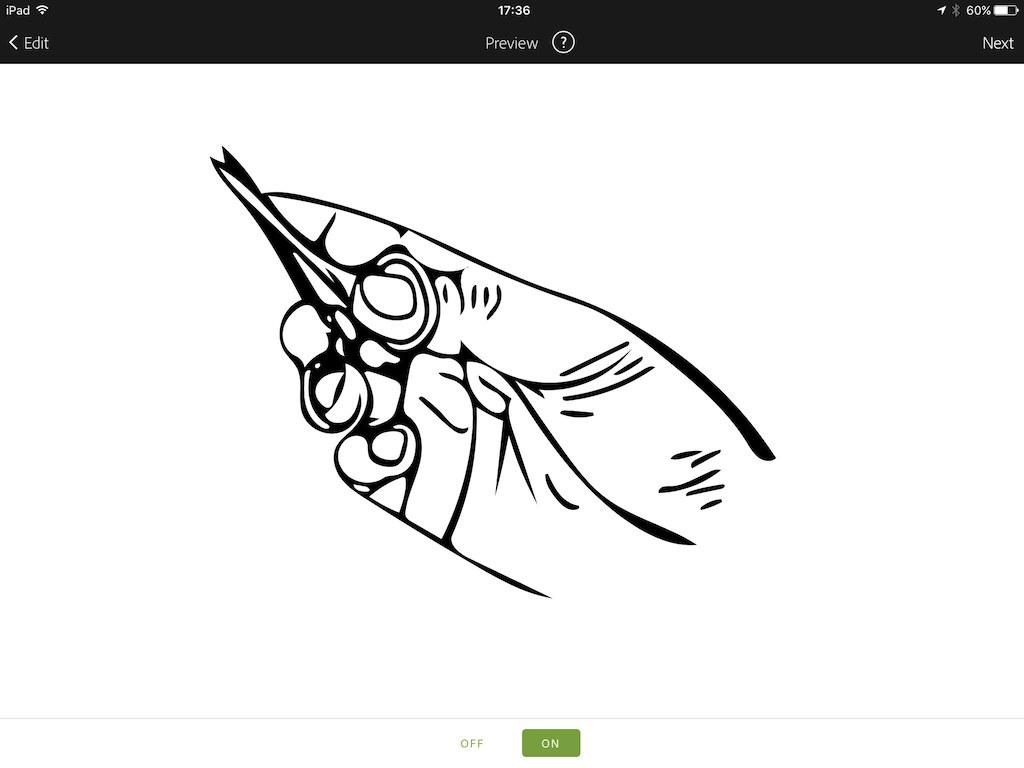
11 隐藏其他所有的图层,
调整shape至合适的大小,双击屏幕,shape印章盖下。
此图层为完成版,如果发现仍有细节需要修改,可以再次重复前面的步骤7-10
完成后,可以导出图像至camera roll,供后续使用。

在写书或者做讲课课件时,可以用本方法制作很多操作示意图。我不确定手术过程中的照片是否容易用类似方法绘制,最差也可以用照片垫底,在上面有笔勾勒一些关键线条,总是比自己完全重绘要简单很多。
对于已经制作好的图片,也可以再利用简单的图像编辑,甚至PPT,就可以更换器械,比如笔可以换成15度刀、月形刀、phaco手柄、chopper钩之类。上面做的拿剪子的动作,也很容易换成各种手术钳。
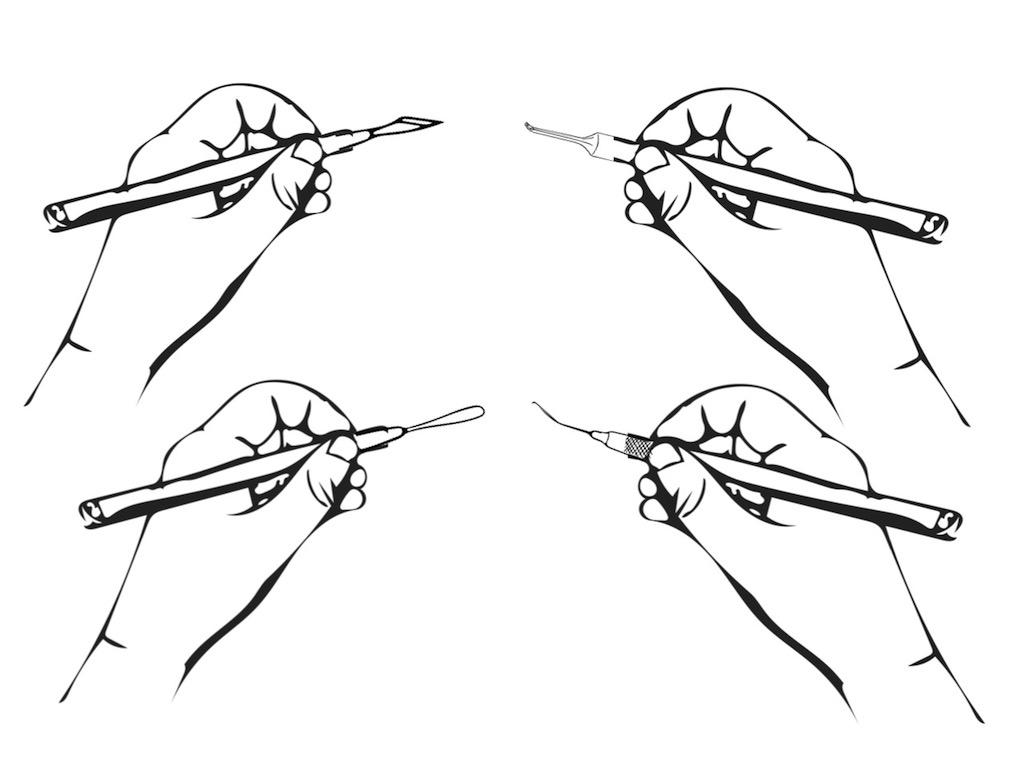
对于眼科的常用手术器械,我之前已经做过了。眼科大夫自用可以从下面链接下载:
https://github.com/goldengrape/phacoTools/raw/master/phaco%20tools.pptx
眼科公司商业使用请联系我。当然也欢迎各公司把自己的产品做成容易在PPT里编辑粘贴的图片,供医生写书和讲课使用。
这个也是吓人. 读书人, 相煎何太急.
end-to-end的一端是原始数据, 另一端是想要的结果. 比如也许从一张眼底照片+FFA直接给出眼底激光应该打哪里, 或者说中文直接给出翻译好的英文字幕. 从一端到另一端中间本来是有很多研究过程在里面的,
好激动, 这是整个机器学习里面最激动人心最吸引人的部分了. 知道了迁移学习这事情以后, 我才比较理解为什么整个课程一直没有进入各种fancy的CNN, RNN之类的神经网络结构, 而仅仅就是把层次多一点的神经网络称为深度神经网络.
这一部分我在做练习题的时候老是错, 我都不是很确定自己理解明白了. 有必要的话最好还是回到课程原始视频中听老师亲自讲.
我觉得这一部分是导师指导/监督学生实验时应该出手的部分.
这是个手工分析操作技巧了. 老师在课程中不断强调不要看不起手工分析, 一是人类看图识别的效率很高, 看上100张图很快就搞定了, 二是在分析过程中还有助于产生直观的印象, 再次利用人类强大的识别能力来解决问题.