面向机器学习的研发思路
这里仅考虑一些实际问题, 对于密码破解之类的NP-hard问题不在讨论范围之内, 对于实际问题, 也只是提供一种可行解.
机器学习/ 深度学习发展很快, 各种算法层出不穷. 我们假定机器学习是一个非常强悍的拟合器(或者分类器, 分类器可以通过拟合器拟合). 在有这样的工具协助下, 研发思路会有完全不同的方向.
那么对于要解决的问题, 要提出以下几个问题:
- 从可以收集到的数据X, 是否存在至少一个通路, 可以推导出结果y?
- 数据集(X,y)是否可以通过低成本的方式获得?
- 数据集(X,y)是否可以通过计算机模拟的方式生成?
如果前两个问题的答案是肯定, 那么就可以直接使用机器学习/深度学习来拟合了.
如果三个问题的答案都是肯定答案, 那么就直接使用计算机模拟的方式产生大量的数据集, 然后在用机器学习/深度学习的算法来拟合.
举个例子:
这个Video Magnification 研究小组做出了一个很厉害的算法, 通过摄像头拍摄画面能够将微小的变化放大, 甚至可以仅仅通过摄像头拍摄面部, 就能够测量心率, 注意不是那种使用闪光灯照亮手指, 然后用摄像头拍摄测心率的方法, 而是直接在自然光照明下, 在一定距离隔空拍摄. 他们还做了一个app 非常有趣.
通过他们的研究, 可以知道:
- 至少有一种算法可以从面部视频(X)计算出心率(y). 条件1满足.
- 数据集(面部视频, 心率)并不难采集, 对同一个人录像+心率带测量就可以采集到这两个数据. 条件2满足.
- 看起来不方便通过模拟的方式产生数据集, 条件3不满足.
所以, 现在如果要实现这个app的效果, 并不需要去解读Video magnification的文献, 不需要去找他们的代码. 需要的只是找到足够多的人, 在不同的环境下录像, 同时监测心率, 取得足够的数据集, 然后送进机器学习/深度学习的拟合器中去拟合, 就可以得到同样的效果.
更进一步,
再来仔细看条件3, 数据集(面部视频, 心率)真的是难以模拟出来的么? 如果我们有Video magnification的算法(实际上有文献有代码), 再找到足够多的单人面部视频, 就可以通过Video magnification的算法得到这些单人面部视频所对应的心率. 单人面部视频在网上很容易找到大量, 于是这个数据集也是可以不需要找真人来录制就可以获得的了. 通过这种方法, 训练出来的深度学习拟合器, 至少不比Video magnification的算法更差, 如果再搭配一些实际录制的数据, 有可能还能做得更好.
这就是面向机器学习的研发思路.
补充关于数据的要求:
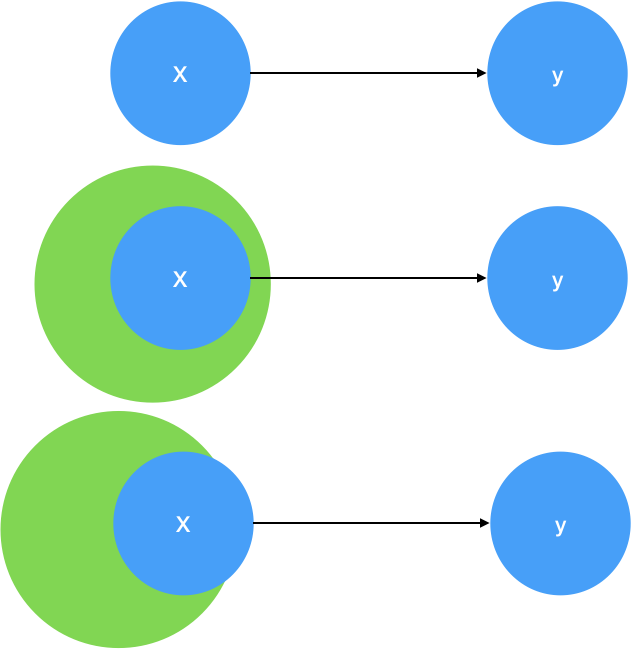 理想的情况下, 我们采集到的数据X可以推导出结果y. 但在实际过程中, 由于我们不知道如何从X推导出y, 只是知道存在有这样一条路径, 于是我们可能只好扩大数据的采集范围, 但只要采集到的数据X, 完全包含了能够推导出y的信息即可, 混杂了一些数据垃圾无关紧要, 可能只是影响了训练的时间, 并不影响最终的预测精度.
理想的情况下, 我们采集到的数据X可以推导出结果y. 但在实际过程中, 由于我们不知道如何从X推导出y, 只是知道存在有这样一条路径, 于是我们可能只好扩大数据的采集范围, 但只要采集到的数据X, 完全包含了能够推导出y的信息即可, 混杂了一些数据垃圾无关紧要, 可能只是影响了训练的时间, 并不影响最终的预测精度.
但在更多的情况下, 有些数据是采集不到的, 我们只能采集到X的一大部分, 有一些关键数据现阶段无论如何也拿不到, 那么拟合出来的结果就一定会有一定的误差, 这时候就看误差是否影响实际需求了. 如果够用, 那就可以了.
另一个例子, 参考End-to-end Optimization of Optics and Image Processing for Achromatic Extended Depth of Field and Super-resolution Imaging, 很喜欢这篇文章的研究思路.