告别美慧

美慧陪伴了我们11年, 于2020年11月29日离开了我们. 昨天我们把她的骨灰撒入了长江.
美慧陪伴了我们11年, 于2020年11月29日离开了我们. 昨天我们把她的骨灰撒入了长江.
乐谱, 是音乐的记录. 但很遗憾, 音乐无法被记录下来, 音乐是即兴的, 流动的, 连续的... 乐谱记录的仅仅是对音乐粗略的描述.
乐谱有很多种类, 简谱、五线谱、音乐游戏里常见的动画...这些都是乐谱. 而且如果它们都可以记录下音乐的话, 它们也都是等效的, 并无高下之分. 就好像是不同的语言, 互相之间可以翻译.
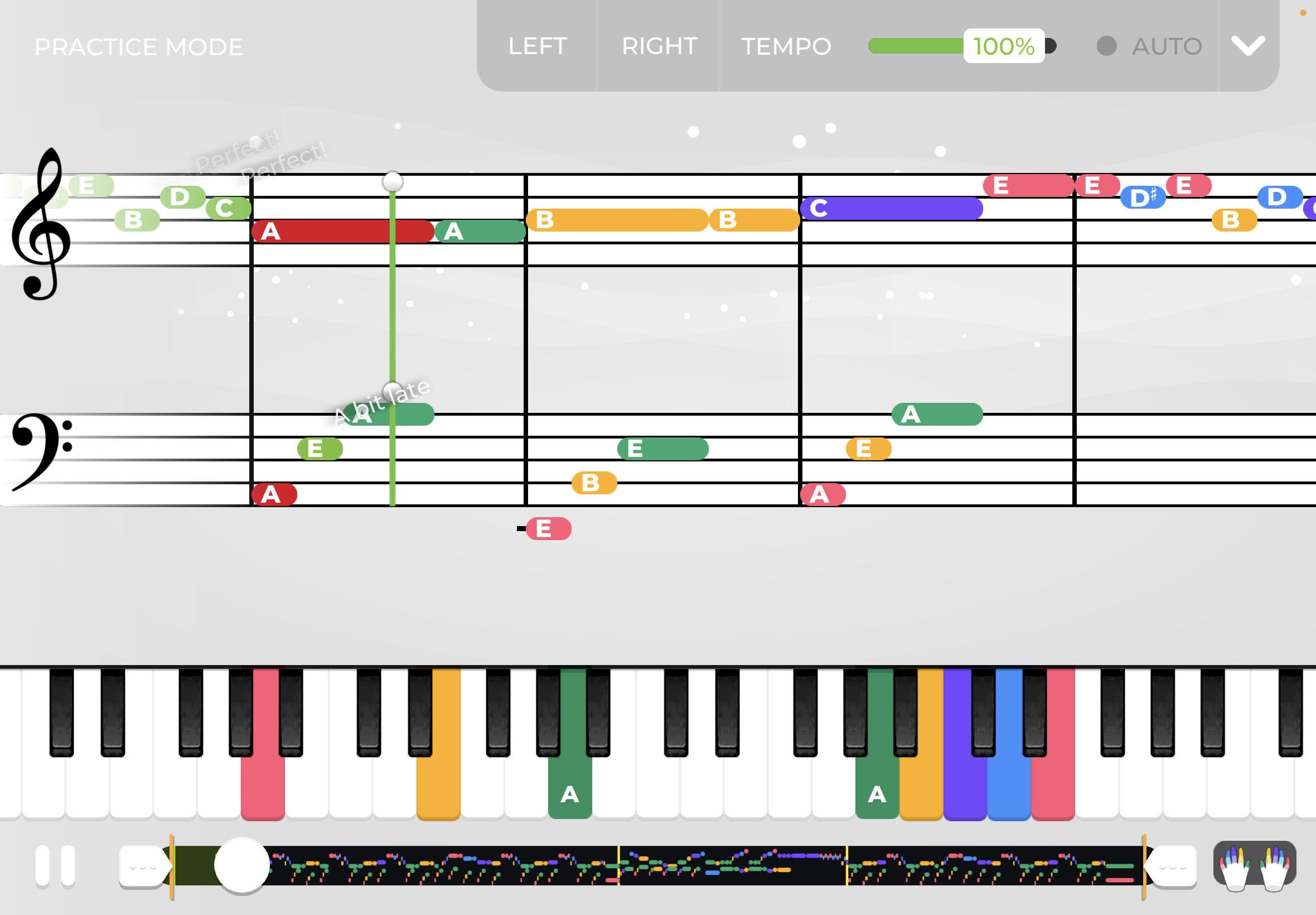
比如yousician里这种乐谱, 用彩条来代表音符的时长, 我觉得比常规五线谱先进多了. 五线谱也是计算机史前遗迹之一.
不过就如同人类的世界里英语占了主导, 乐谱里五线谱也是不能避免的, 错过了五线谱实在太可惜了.
下面, 我们开始学习五线谱.
你多多少少应该已经听过高音谱号、低音谱号、全音符、半音符等等一大堆有的没的, 这些小学中学的音乐课都应该讲过. 甚至慢慢数, 你也能逐一推导出每根线的音高.
真正困难只是长时间不看, 就对不上哪根线和哪个音了. 所谓学习五线谱, 其实就是要建立起谱线上的位置和每个音之间的反射联系, 看到这个音符, 就知道唱什么(唱得准不准另说).
所以, 我们的目的, 就是建立反射, 快速的反射, 这是需要练习的, 有很多练习方法都可以, 不一定是通过乐器, 其实用电脑就很好.
比如, 输入乐谱.
这就像是在练习打字, 你看着文字, 然后手指在电脑键盘上按键; 在输入乐谱时, 你看着乐谱, 然后依次录入每个音的音名. 一开始可能很缓慢, 要一格一格数, 但慢慢输入多了, 速度就会快起来.
而且, 输入乐谱这个技能不论是扒歌还是作曲, 都是用得着的技能, 拿来练识谱不浪费.
直接上作业:


注意:
最重要的注意事项:
就不练琴!
就不练琴!
就不练琴!
乐器演奏是音乐的一部分, 但仅仅是一部分, 乐器演奏不等于音乐.
...
(会吹口哨, 恭喜, 你已经学了一部分音乐)
简单类比一下, 语文课上老师会教写字, 甚至可能会教如何把字写得好看, 但书法和文学完全是两回事, 就像字写得好和作文写得好完全是两回事一样.
所以, 一个人乐器演奏得好, 他是一位演奏家, 不一定是一位音乐家.
演奏是一种技巧, 需要大量刻苦的练习————简单说, 反人类. 有可能成人能够从演奏练习中获得乐趣, 那是一种忘我的心流状态, 可以短暂逃离日常工作和生活中的烦心事. 我不相信儿童能够体验到演奏练习的乐趣.
而且, 和任何专家一样, 只有极少数的人可以成为专业的演奏家.
通过学习演奏来学习音乐, 事倍功半. 那只是计算机史前时代的历史遗迹. 现在已经有了非常多的工具可以直接将自己的心情通过音乐表达出来, 用上它, 跳过枯燥的演奏练习.
本教程就是基于这样的想法建立的: 你可以五音不全, 可以没有节奏感, 可以笨手笨脚, 可以没有乐器...这些都不能阻止你学习音乐.
接下来, 我们开始第一课, 认识五线谱.
按照上集的方式进行收纳, 将所有的零碎物品装入同一型号的纸盒、纸箱, 并且建立索引文档以后, 就可以开始LRU收纳和LRU断舍离了.
LRU, 是Least Recently Used的缩写, 即最近最少使用, 是一种缓存清理算法, 将闲置不用时间最长的内容清理掉.
尽管创新性高速缓存方案品种繁多,其中一些在适当的条件下甚至可以击败最近最少使用法,但是最近最少使用法(以及在该策略基础上做出的一些细微调整)仍然深受计算机科学家们的喜爱,并且在开发各种应用程序时得到不同程度的应用。----《算法之美--指导工作与生活的算法》
几个问题反复被问到, 为了自己方便, 所以干脆写在一起, 以后直接转发就好了.
就我多年被咨询的经验, 以及非正式不严谨的统计, 得到的感觉是, 儿童眼疾最常见三大问题: 近视、眼皮长包、外伤. 这三个问题也是能够在家长的努力下得到预防或者控制的事情. 所以还是值得拿出来说一说.
按照严重性依次说明:
理想的提神醒脑工具, 最好能够招之即来挥之即去, 能够在需要的时候保持清醒, 在不需要的时候又不至于影响睡眠.
没有.
对于我, 比较接近的工具是咖啡因. 或者说含有咖啡因的零度可乐. 喝完以后很快可以提神, 但我无法快速清除它, 所以哪怕只有200ml的可乐也能让我失眠到3点. 平时可以睡到自然醒所以也无妨.
最近需要连续两天长途开车, 不得不连续大量服用零度可乐, 夜里的失眠也不可接受. 所以只好查找能够快速清除咖啡因的方式.
查到了一篇关于咖啡因代谢的综述, 收获良多. Interindividual Differences in Caffeine Metabolism and Factors Driving Caffeine Consumption. 全文 https://pharmrev.aspetjournals.org/content/70/2/384
在以前的《收纳学导论》中, 我们已经介绍了“收纳”这个词汇的含义:
在本讲中, 将对《收纳学导论》中的理论知识进行实际应用. 本讲使用的是收纳活动强度最高的__搬家__过程. 在搬家活动中, 为了方便运输, 需要将居家物品进行高强度的收纳, 而到达新居以后, 又要将物品恢复到使用状态. 以下详述之.

上一次写《如何拒绝进入美丽新世界(1)》还是在8年前, 这世界还真是改变了不少. 所以, 续写一下.
如果有一个异世界是由另一个生物创造的, 它在这个世界中享有绝对的控制权, 它可以控制包括但不限于物理定律的所有事情, 那么你敢进入这样一个世界么?
听起来很危险吧.
但现实中就有这样的类比, 开放的网页vs App. 从网页中获取信息, 你可以选择不同的浏览器, 可以控制流入的信息, 可以对显示的内容进行加工、提取、转换等等, 也可以控制流出的信息. 在App中, 特别是手机app上, 你没有能力加入自己的组件, 你只能被动接受产品经理提供的“功能”.
对于近未来, 但愿我们还能继续使用现金.
再远一点的未来, 或者科幻小说中, 也可能会有这样的类比. 用脑机界面接管大脑所有的神经活动, 然后将意识数字化, “上传”到某个网络中. 嗯, 听起来这就是最可能的永生方案了. 永生啊, 谁不想呢? 不过, 在此之前, 一定要看看上传的那个框架是怎样的, 是独立实体么? 它建立在哪些系统之上? 受到哪些控制? 能够退出么? 能够退出么? 能够退出么? 死亡是最后的自由.
如果你选择了一个可以自己控制的框架, 就有可能控制自己的生存环境了.
举例:
你已经知道可以使用ublock origin https://ublockorigin.com/, 但其实广告拦截插件不仅仅能够拦截广告, 或者说广告的定义可以被修改, 网页上任何你觉得不想要的模块都可以被拦截掉.
比如淘宝的首页, 完全可以打扫成google首页一般清爽.
信息尽量少从推送获得, 而是自己主动去获取信息.
用上面的裁剪工具, 你可以把所有推送来的“推荐”信息给拦截掉, 当然还有用户评论.
需要什么信息我自己搜索, 自己去看, 不要给我推荐. 我的评价我自己体验, 不需要别人先说. 类似的, 对于纸质书, 书的序、前言什么的, 我都先直接撕掉.
但如果还是需要一些推荐呢? 如果一定要表明自己的喜好, 那么, 透露出我不喜欢的信息更高效一些.
比如对豆瓣FM, 我非常喜欢播放器里那个“垃圾桶”按钮,

没有“不喜欢”按钮的流媒体是不值得使用的.
一旦发现一个歌手自己不喜欢, 一定要坚持追杀, 追杀到该歌手的页面, 把他所有的精选歌曲送进垃圾桶, 这个操作其实非常快捷, 快速连续点击就可以了. 然后要株连, 与该歌手相似的前三位, 也应该照此办理, 再多诛杀一层, 九族.
这样的结果就是我目前使用豆瓣FM可以放心开一整天, 不会有什么刺耳的声音出现.
要经常欣赏人类的智慧
在medgadget看到床旁核磁的新闻: https://www.medgadget.com/2020/08/swoop-portable-mri-cleared-in-u-s-for-bedside-scans.html

这家叫HyperRefine的机器通过了FDA的认证.
真是很厉害, 印象中做核磁还必须是在一间电磁屏蔽的屋子里, 现在居然已经可以推到床旁去做了.
其他科的同学也觉得不错:
“神经内外科的兄弟们不用再抬着气管插管的昏迷病人过床了”
“移动CT、核磁对于急性卒中救治非常重要,尤其是院前转运途中就可以实施,将大大节省时间,增加时间窗内溶栓和取栓受益人群。值得期待。”
和放射科的同学聊了聊.
“这款hyperfine用的是0.06T的永磁体, 成像效果可能和我们熟悉的超高场强相去甚远“ “最早普及的mr也需要0.2T吧,很模糊,扫描时间也长。但是1.5T以上的超高场强肉眼看上去都差不多了。“ “目前hyperfine的策略貌似是先训练AI识别图像“
感觉这才是深度学习的正道, 用算法弥补硬件, 产生曾经不可能的应用场景.
于是来了兴趣. 简单检索了一下.
Hyperfine的主要技术方案在WO2020028257A2 这个专利里, 全文: https://worldwide.espacenet.com/patent/search/family/067659966/publication/WO2020028257A2?q=pn%3DWO2020028257A2
用了U-net, NVN, GNVN几个深度学习网络, U-net以前见过, 是先压缩, 然后再展开成高分辨率, 在AI for Medical Diagnosis课程里提到过: https://www.bilibili.com/video/BV1JT4y1g74P?p=34
GNVN具体的算法描述在这篇论文: https://msofka.github.io/pdfs/schlemper-miccai19.pdf
类似的技术还可以用在超声和CT上, 发明人之一Michal Sofka, 同时还在给其他几个公司提供算法. https://msofka.github.io/
采样扫描的顺序不是横竖扫, 可能是三角形或者其他什么形状的网格.
专利中提到用来训练的数据集其实不大, 只有1200个 https://www.humanconnectome.org/study/hcp-young-adult/document/1200-subjects-data-release 当然可能在实际上市之前还能再找到些数据.
虽然觉得是很了不起的事情, 但对临床医生提示一下: 小心使用了机器学习、深度学习、AI的设备, 所见到的图像不一定是“真实”获得的, 有可能是机器“脑补”的. 比如之前说华为的手机可以拍到月亮, 但是拿着对着盘子拍, 也能补上月亮的环形山.
类似的, 如果在训练用的高清数据集里, 眼球的图像都是完整的, 在眼眶附近出现的总是一个完整的圆环, 在低分辨率的情况下, 比如有几个像素缺失了, 或者这个区域看不清楚, 机器可能就按照高清数据集里常见的方式进行填补, 于是就把眼眶附近“画”出一个完整的圆环. 但如果这个病人有个穿通伤, 恰好就在一两个像素的范围内有异常, 而在训练用的数据集里这种情况很少, 或者压根没出现过, 深度学习就会把这一两个像素当作是噪声, 用一个完整的眼环给替代掉.
目前已知它的数据集只用了1200张, 即使是大量也只可能是几万张十几万张图, 毕竟放射科大夫们很贵. 分配到每一个病种、或者说每一种图像细节的数量会更低一些. 比如十万张核磁, 里面有1千张眼球破裂伤的, (其实就不少了, 每天1个得收集3年多呢), 对于AI来说, 如果看不清楚, 就蒙一个完整眼球, 这样的准确率还可以高达99%. 如果是疾病诊断之类, 可以用ROC曲线来矫正准确率, 但如果是图像细节恢复, 可能挺难的. 还只能用类似准确率的方式描述, 那么面对发生率较低的细节判读时, 临床医生要小心.
这篇极简科普是关于:
这些都是一个领域的东西.
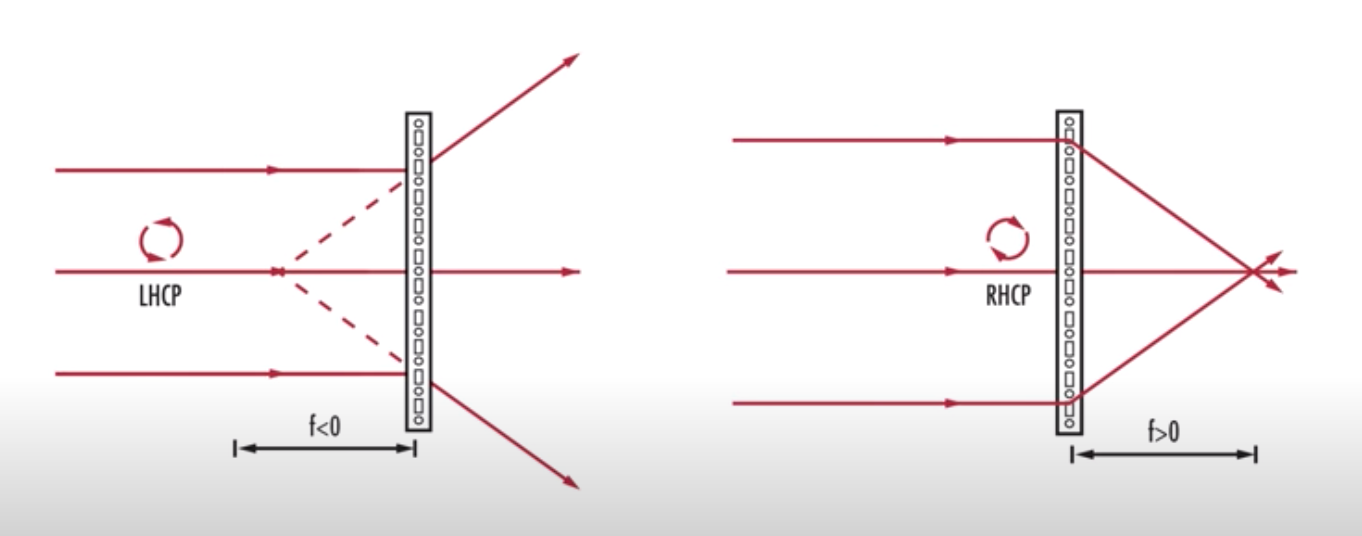
近期研读VR文献和专利, 反复发现Pancharatnam Berry Phase透镜这个东西, 如果入射光是圆偏振光, 可以产生相反的屈光度, 比如对于右旋圆偏振光(RCP)是+3D的透镜, 对于左旋圆偏振光(LCP)的就是-3D, 实在是非常魔法.
作为一个已经认真学习本领域技术1整天, 认识本领域专家的学生的师兄的哥们的, 不写剧情与人物的科幻小说(发明专利)作家. 我认为自己已经有足够的资格来撰写一篇极简科普. (没错我就是在黑各种极简).
本极简科普是以临床眼科医生为假设读者撰写的, 就是那些听见“像差”就呵呵, 看见公式就晕过去的家伙们.