眼科数据随机森林
要讲解"随机森林", 先要简介一下"决策树". 各位眼科大夫在眼科门诊每天都在用"决策树", 比如一位单侧眼痛伴同侧头痛的病人进入门诊:
- 眼压>21mmHg吗?
- 不是, 考虑其他可能
- 是的, 考虑青光眼可能, 还有鉴别诊断1, 2, 3..., 进入下一题
- 前房浅吗?
- 不是, 考虑其他可能
- 是的, 考虑急性闭角型青光眼发作, 还有鉴别诊断x,y,z...,, 进入下一题
- 瞳孔光反射存在吗?
- 存在, 考虑其他可能
- 瞳孔固定, 考虑急性闭角型青光眼发作, 进入下一题 . . . .
这就是一颗"决策树", 就是一堆判断题, 一层一层筛选, 最终将数据(病人)分成几类(急闭, 其他)
"随机森林"就是由一组这样的"决策树"组成的分类器.
随机森林的优劣
优点就是简单好用:
- 它对输入的数据没什么特殊要求, 不需要很严格的预处理, 比如不需要归一化, 不需要正态分布化. 定量的数据也行, 定性的数据也行. 完全不挑食.
- 它得到模型预测准确率还不差, 甚至使用默认参数也不差. 如果用同样的数据集实验, 不用深度学习的话. 随机森林的准确率大概可以排进前三.
- 需要的数据量和运算量, 都还是在可接受范围内, 比如一两百个的数据, 用笔记本电脑跑上几分钟, 也许就能给出不错的结果.
缺点:
- 结果不好解释. 不过大概除了线性模型, 哪个机器学习出来的结果都不好解释.
- 还是属于"传统"的机器学习方法. 有些太复杂的问题还是需要深度学习来做.
所以, 个人意见是遇到问题先用随机森林试试呗, 不好再换深度学习.
随机森林代码
通过python scikit-learn建立并且训练一个随机森林模型的代码非常好写, 实际上只有两句话:
clf = RandomForestClassifier() clf.fit(X_train, y_train)
比较复杂的是如何标记数据, 如何把数据读取进来, 如何把数据整理清洗拆分. . . 干些体力活, 得到X_train, y_train这两个东西.
程序世界的好处是, 体力活大多只需要干一次, 做好模板, 以后就轻松了. 所以我就在这里把眼科这部分的脏活累活先做好.
目前支持的有医疗设备已经有: Sirius角膜地形图 PentaCam角膜地形图 Grand Seiko WAM5500视调节力测量仪 Humphrey视野(PDF需预先处理) * HRT(PDF需预先处理)
开源项目已经放在github上, 推荐通过微软的azure notebooks在线使用, 使用azure notebook的教程, 请参考这篇教程
眼科数据随机森林模型的使用方法
上传数据
如果你用的是微软azure notebooks, 那么在clone本项目以后, 可以设定成私有项目, 这样再传数据的时候, 不至于泄露给其他人. 你需要用浏览器在云端建立一个目录, 然后把医疗设备的数据报告一个一个上传上去, 看网速吧.
如果你已经有能力在本地运行python, 甚至装好了anaconda,pandas,scikit-learn, 那无需太多解释, 你只需要把数据放在程序能够找到的路径里即可.
PDF数据预处理:
目前能够处理的是HRT和Humphrey视野计两种PDF报告, 找到python/pdf_parser目录,
分别按照HRT.ipynb和Humphrey_VF.ipynb文件中的要求, 修改好路径, 运行. PDF文件的报告会被转换成csv文件.
csv文件是"逗号分割的"电子表格文件, 可以方便使用excel编辑或者查看, 记得编辑完成后使用"另存为"csv文件.
class.csv文件设定
需要使用excel编辑这样一个表格, 示例请见\testdata\class.csv
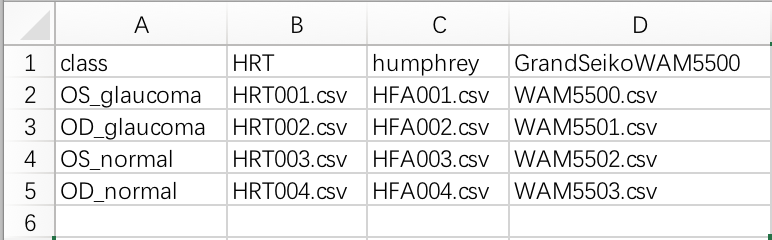 第一列是class, 记录每一行所代表的病人的诊断, 有病/没病, 也可以有多个诊断.
第一列是class, 记录每一行所代表的病人的诊断, 有病/没病, 也可以有多个诊断.
之后的每个单元格里填入的是该病人的数据文件名, 其中列标题要注明是哪种设备. (注意大小写, 业余作品不要太挑拣)
分析项目设定
需要使用excel再编辑一个表格, 示例请见\testdata\analysis_category.csv
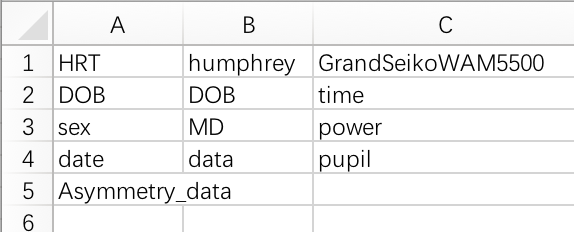
列标题是设备的名称, 每个单元格里是需要分析该设备数据文件中的哪些项目, 项目的名称在各个设备的json中找, (注意大小写, 业余作品不要太挑拣)
GrandSeikoWAM5500中的项目有: date: 检查时间 start_time: 检查开始时间 eye: 眼别 time: 测量时间点 power: 屈光状态 pupil: 瞳孔直径
HRT中的项目有: "DOB": 出生日期, 操作员不一定都好好填的 "sex": 性别 "date": 检查时间 "OS_data":左眼数据 "OD_data":右眼数据 "Asymmetry_data": 非对称数据 * "classifiction": HRT设备给出的分类诊断, (不建议包含)
humphrey视野计的项目有:
- "DOB":生日,
- "eye": 眼别
- "date":检查日期
- "False POS Errors":假阳性
- "False NEG Errors":假阴性, 这两个是判定视野检查质量的
- "VFI": 忘了是啥了.
- "MD": 平均缺损, 有重要随访意义
- "PSD": 又忘了是啥了
- "data": 这是二维的视野数据, 在送进随机森林的时候, 会抻成一列使用, 所以左右眼的排布会是不同的.
pentacam角膜地形图: "FRONT", "BACK", "Cornea", "Pachy", "Chamber","K", "Pupil", "X", "Y" 注意, 这些数据里大多也是二维数据, 将抻成一维使用, 左右眼可能会有不同.
sirius 角膜地形图: "Radii":, "CornealThickness":, "ElevationAnterior":, "ElevationPosterior":, "RefractiveEquivalentPower":, "RefractiveFrontalPowerAnterior":, "RefractiveFrontalPowerPosterior":, "SagittalAnterior":, "SagittalPosterior":, "TangentialAnterior":, * "TangentialPosterior": 这里面数据好多, 也是注意二维数据的问题, 要注意左右眼的问题.
运行随机森林模型
随机森林模型在python/random_forest_model.ipynb, 如果设定好class.csv和analysis_category.csv, 大概就不需要什么修改,可以直接训练了,
训练完成后要观察一下ROC曲线和AUC评分. ROC曲线越靠近左上越好, AUC评分越接近1越好. 在该文件中, 我也有说明如何进行进一步的参数调节和优化. 但, 如果AUC评分巨高就直接发文章好了, 如果AUC评分接近0.5, 就算了吧, 换深度学习方式好了.
最后, 这是一个业余项目, 代码并不完善, 还在缓慢而持续地改进中.