octopus视野报告数据提取
又写好了一段PDF报告数据提取的小程序, 这次是针对Octopus 900动态视野计的. 可以提取PDF的视野检查结果报告中的数据, 能够提取的数据包括: 姓名, 生日, 检查日期, 眼别, 检查程序名称, RF, MS, MD, sLV, 还有视野测量的原始数据.
提取出来的数据保存在csv文件里, 可以使用excel打开和处理.
 其中以G standard程序测量的原始数据是按照从中心开始顺时针螺线的方式排列成一行的.
其中以G standard程序测量的原始数据是按照从中心开始顺时针螺线的方式排列成一行的.
也可以处理一个一个文件夹下所有的PDF报告, 把提取的数据汇总到一个csv里面.
项目文件开源, 放在在github上, 如果已经比较熟悉github, python和jupyter, 打开看看就很容易理解.
注意: 目前我还只能处理未加密的PDF, 并且PDF的页面大小必须严格是A4, 否则无法取得数据. 切记切记.
但如果以前没怎么接触过python, 又临时需要处理些数据, 那么以下是使用教程:
云端运行
如果不是写python已经比较熟练的人, 我一般不推荐在本地计算机上安装python和相关的工具包, 很容易出错. 我建议是在云端运行, 可以选择的服务商很多, 但微软的 Azure notebook 免费, 国内可以访问, 还可以运行私有项目以免泄露病人数据, 因此比较推荐.
1. 打开微软的Azure notebook, 地址是https://notebooks.azure.com , 点击页面右上的Sign In, 使用微软账户登陆, 如果没有微软账户的话, 需要自己注册一个.
2.
登陆进来以后, 点击左上的Libraries, 将列出您已经建立过的Library, 如果以前没用过, 下面是空的.
3. 点击 + New Library, 建立一个新的Library.
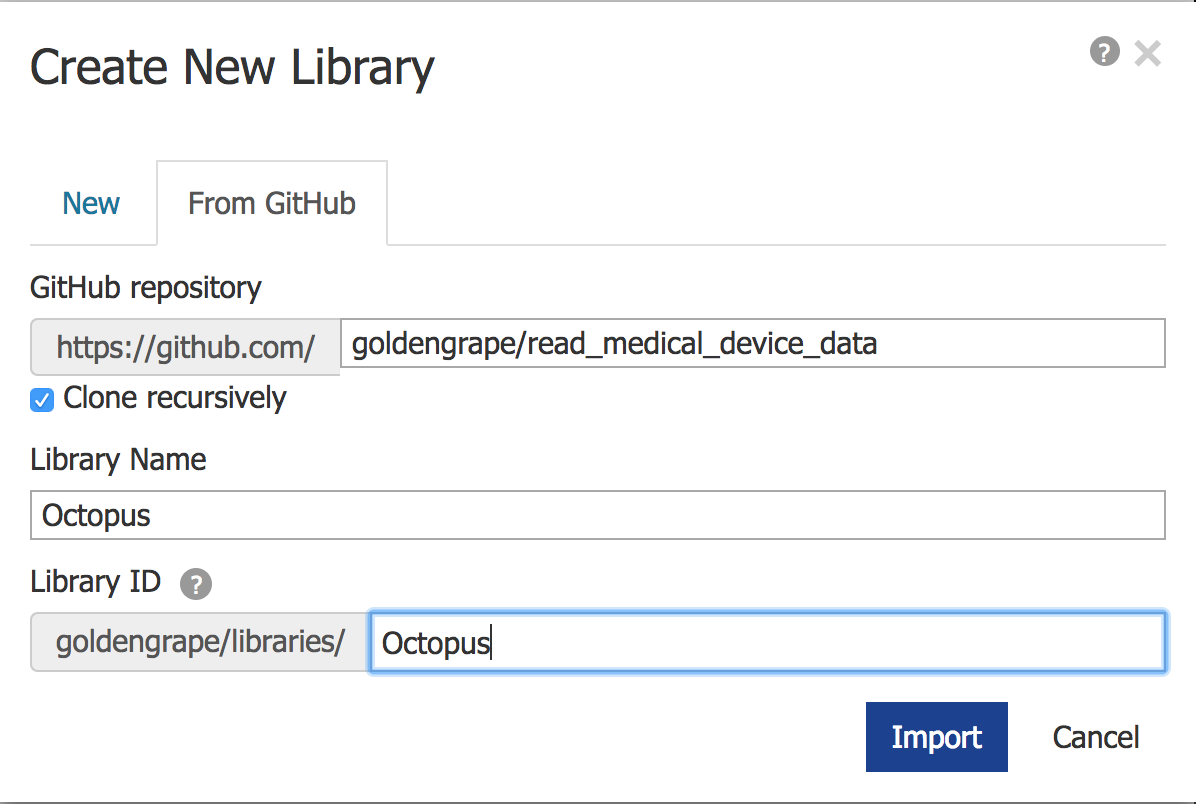
- 在选项卡中, 选择From GitHub,
- 在GitHub repository里面填上https://github.com/goldengrape/read_medical_device_data
- 给自己的Library起个名字, 再起个ID, 比如都叫Octopus
- 然后点击Import
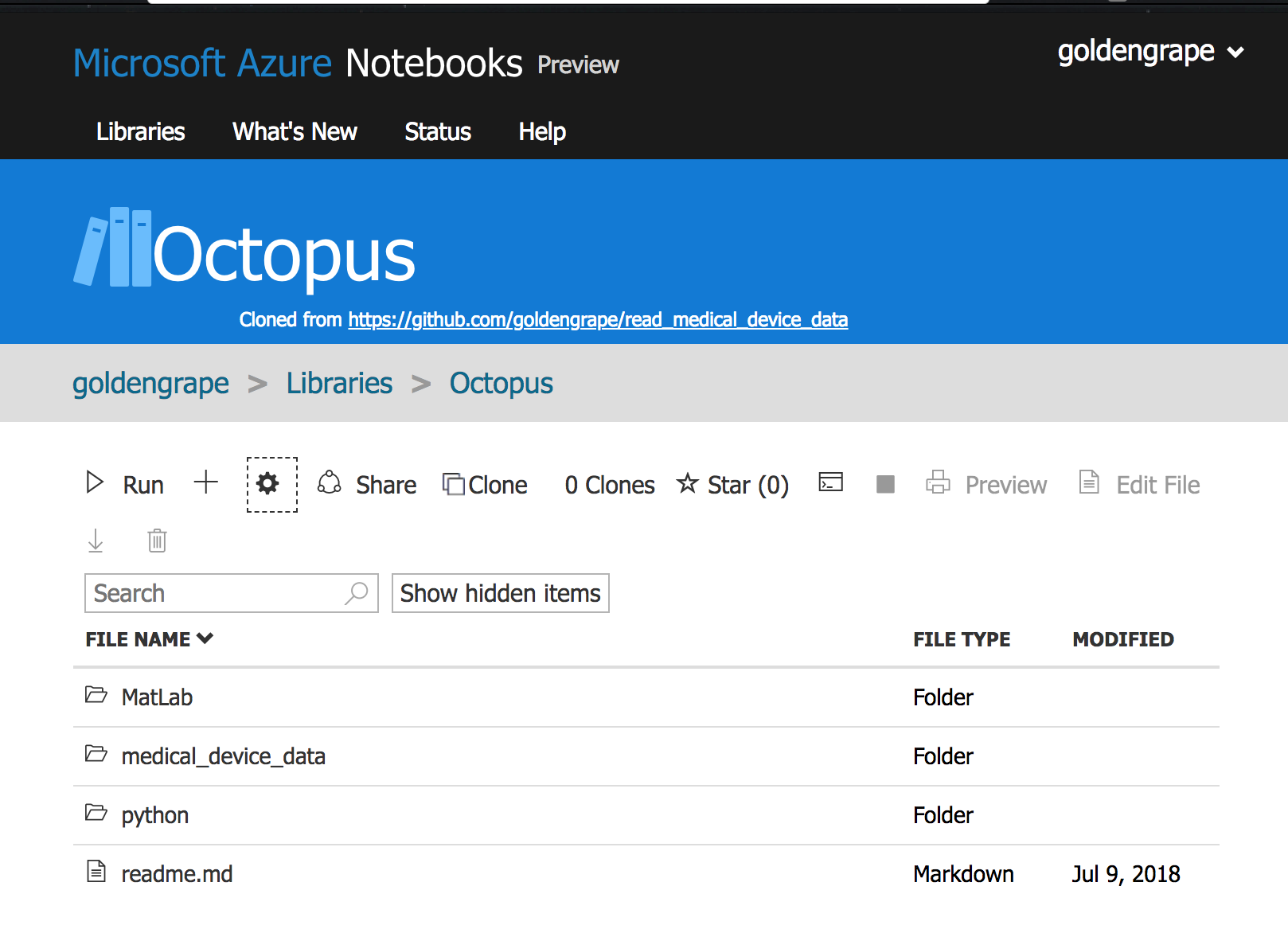
4. 稍等, 或者刷新一下页面, 你会看到刚才建立的Library已经出现了, 点击进入.
上传数据
1.
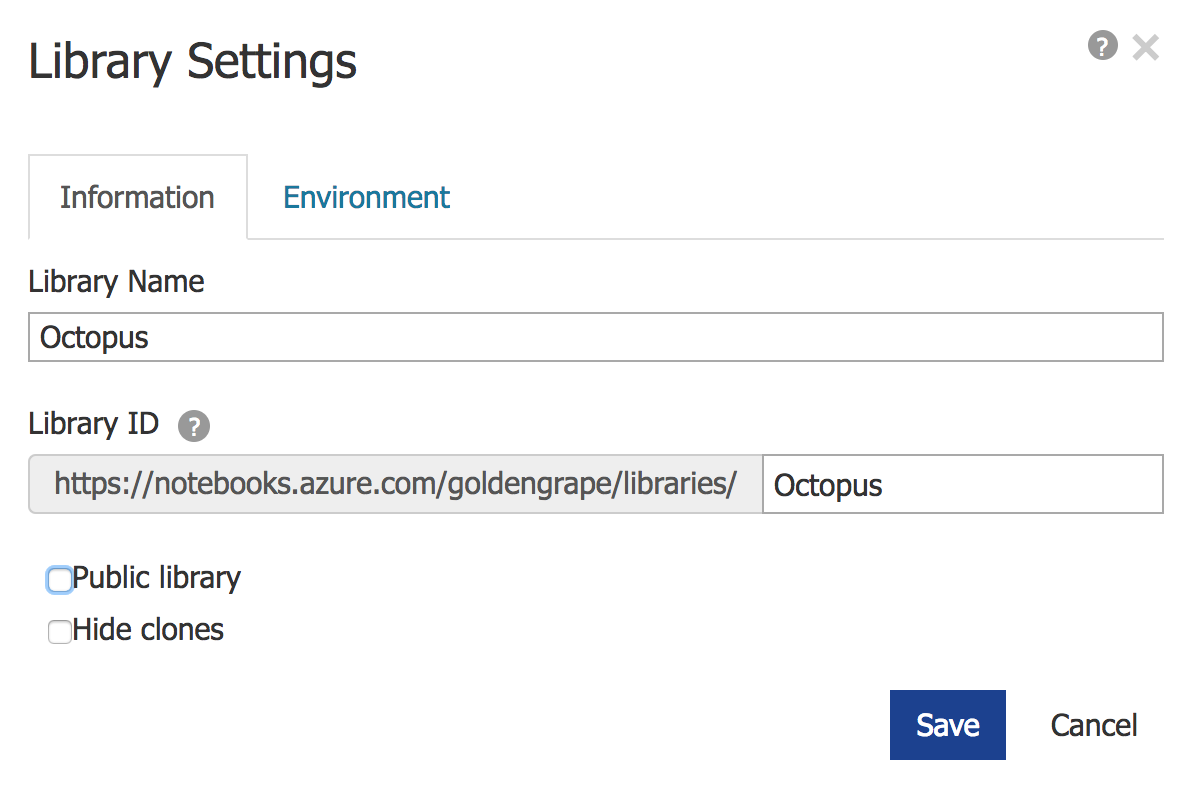
在上传数据之前, 先把这个Library设定成私有,
 点击齿轮⚙️图标
点击齿轮⚙️图标
把Public Library前面的钩去掉, 然后Save
2.
点击加号➕图标, 就在刚才的齿轮⚙️左边.
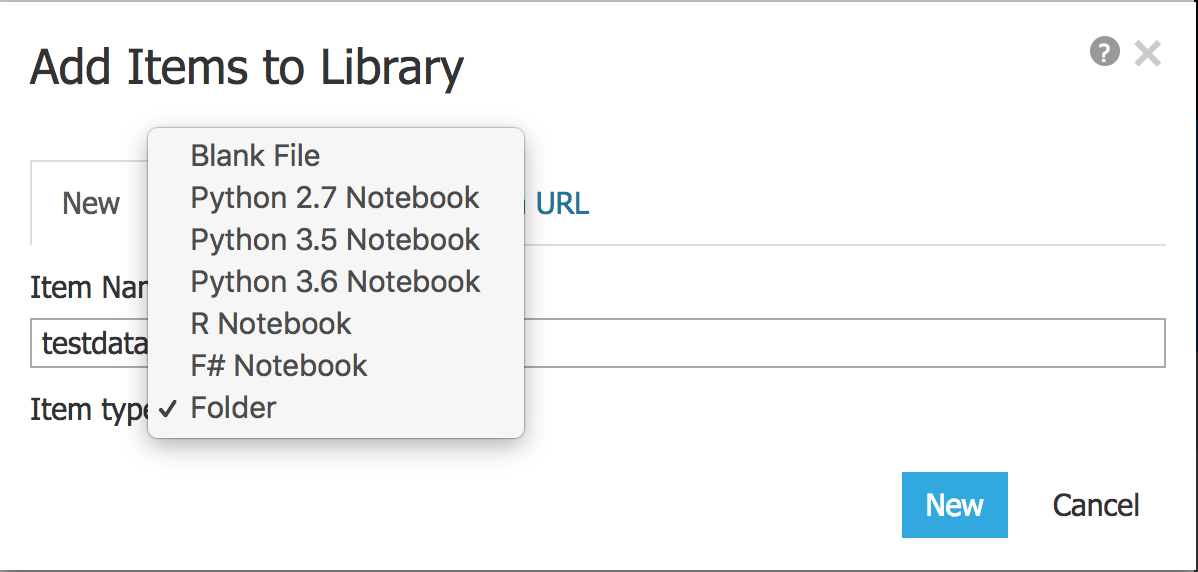 在item type里面选上Folder, 给自己的数据文件夹起个名字, 比如testdata, 然后点击New
在item type里面选上Folder, 给自己的数据文件夹起个名字, 比如testdata, 然后点击New
3.
你会发现出现了一个testdata的文件夹, 跟电脑上差不多的操作, 点击进入
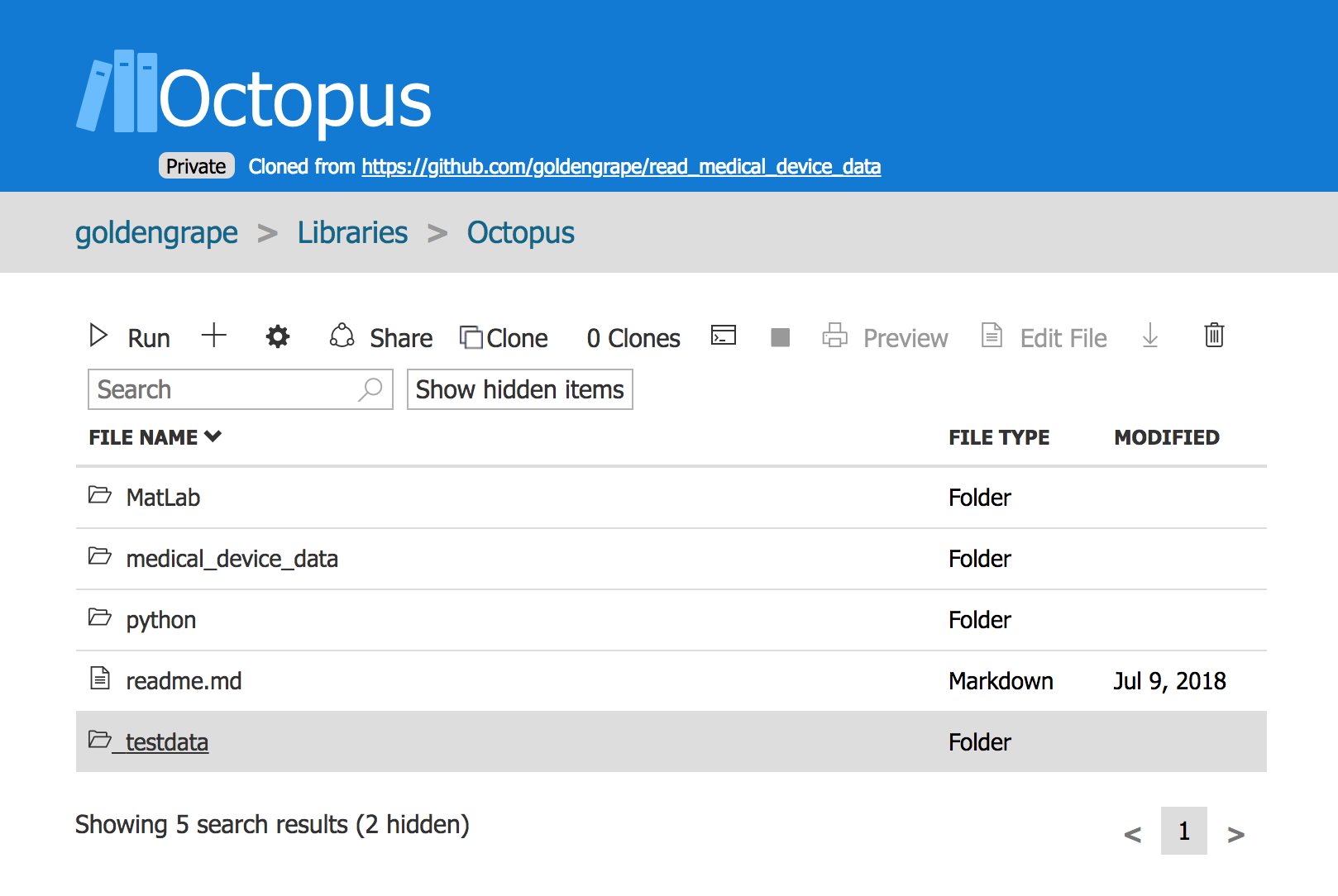
4.
再次点击加号➕图标, 这次选择From Computer
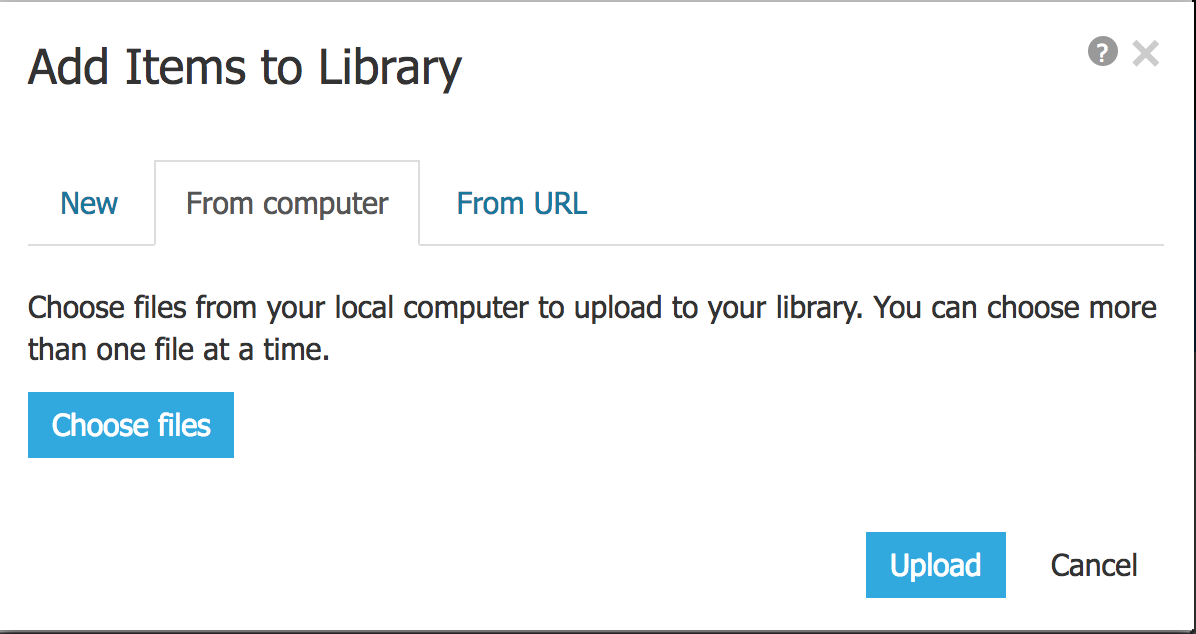 然后点击Choose files, 会打开本地文件的选择器, 选上要上传的文件.
然后点击Choose files, 会打开本地文件的选择器, 选上要上传的文件.
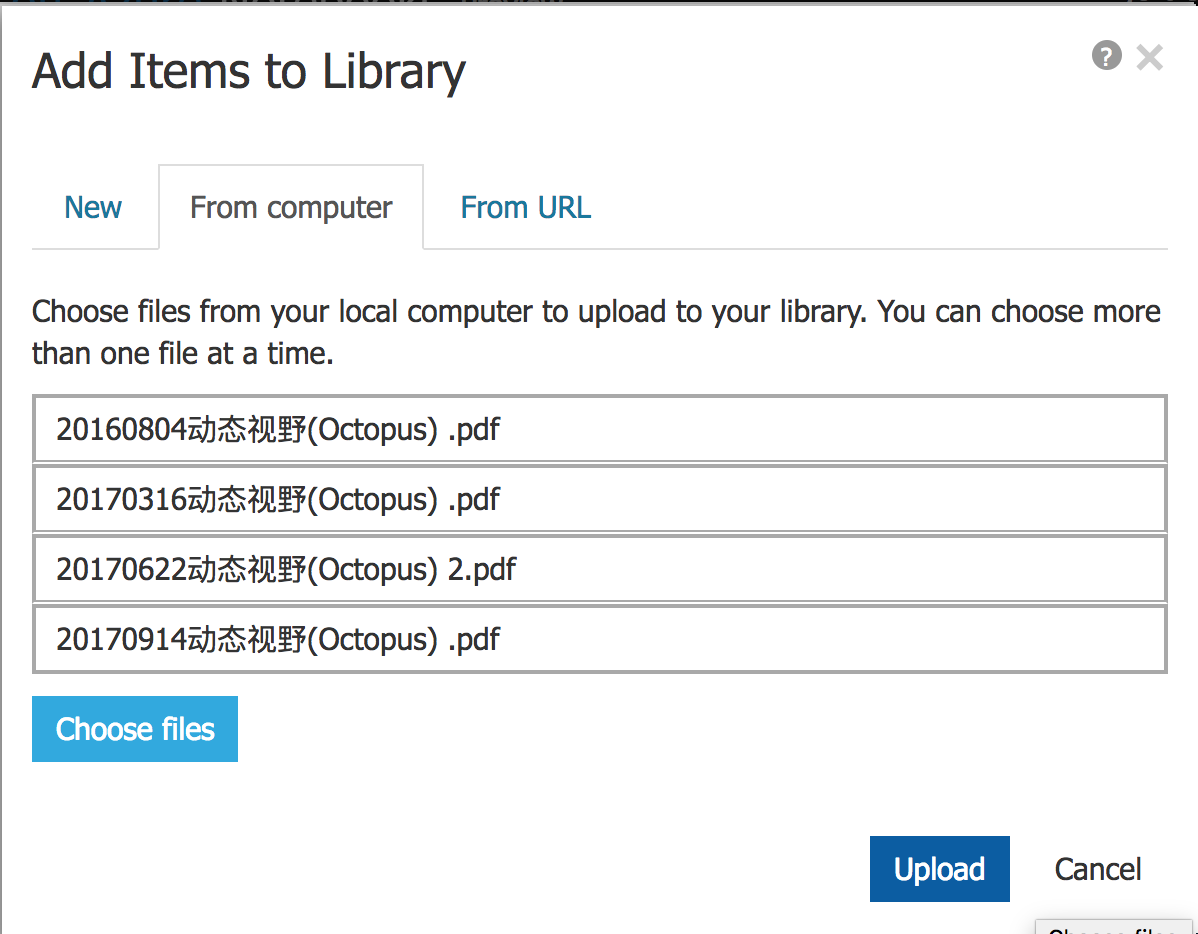
 然后upload, 跟发邮件时添加附件的动作没什么区别.
然后upload, 跟发邮件时添加附件的动作没什么区别.
设定参数
1.
点击Library > Octopus > testdata 中的Octopus, 回到上一级目录
2.
依次进入目录, 到Octopus > python > pdf_parser
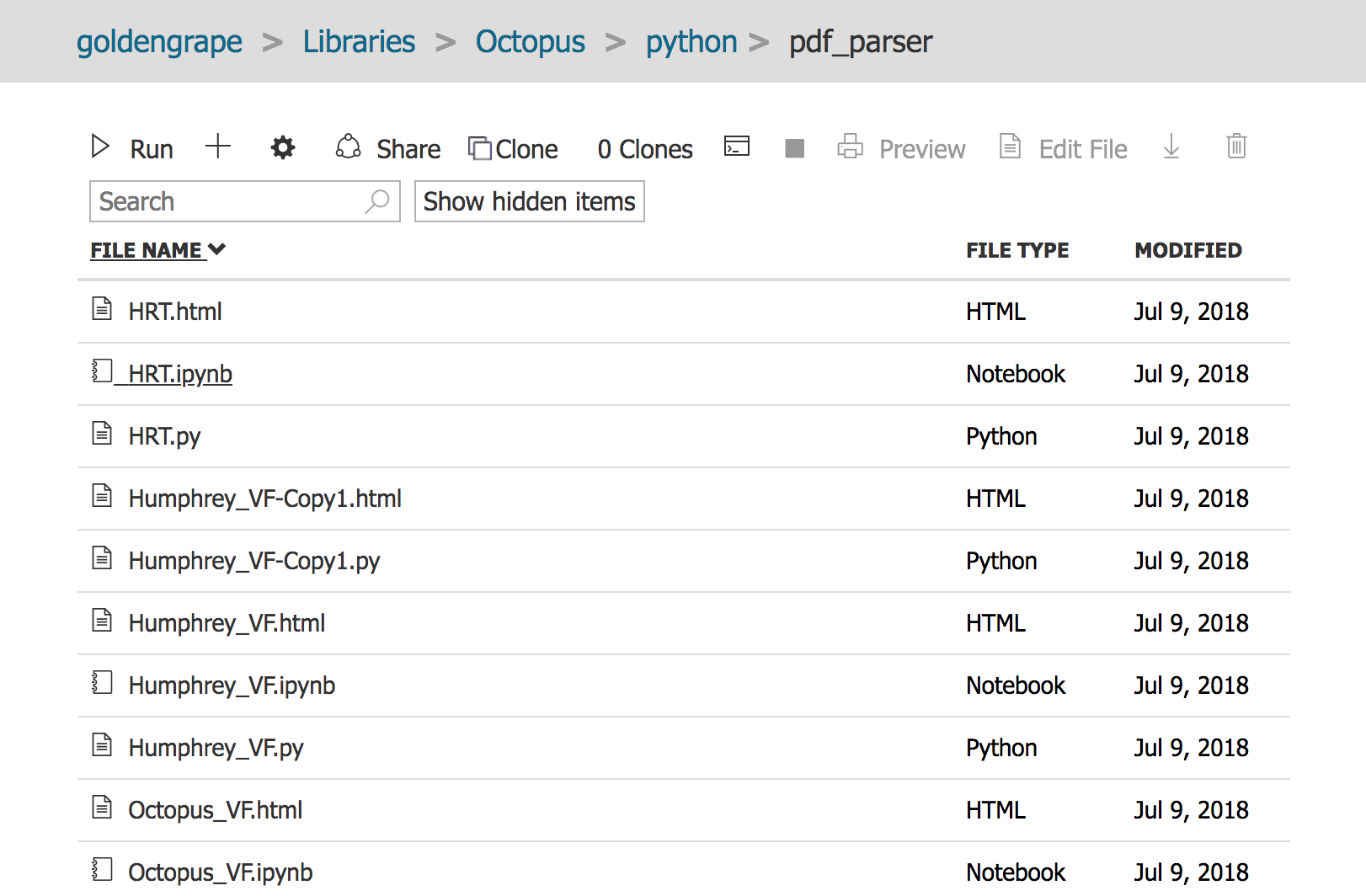 找到Octopus_VF.ipynb, 点击打开
找到Octopus_VF.ipynb, 点击打开
3.
打开这个ipynb文件以后, 就进入这样一个页面:
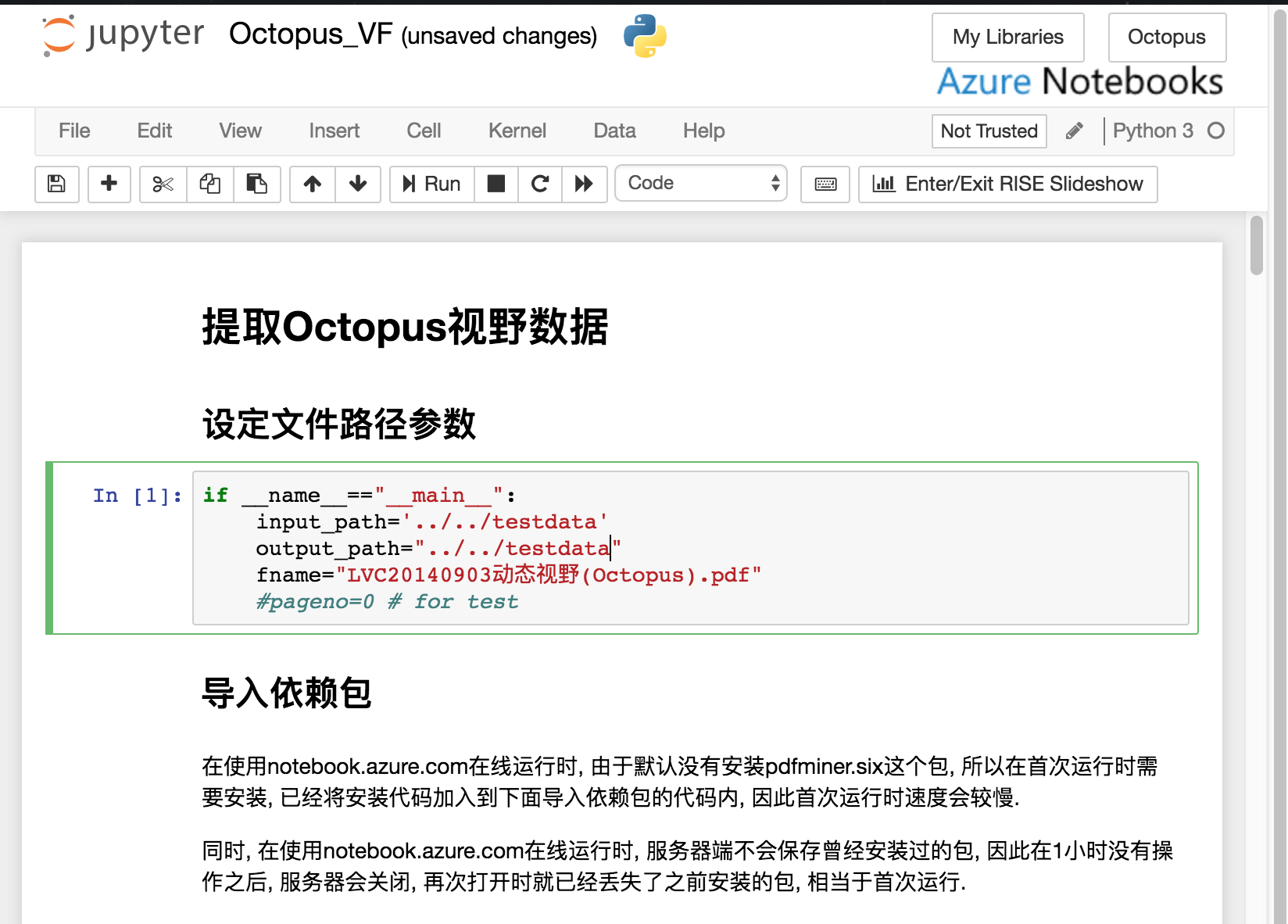 把input_path修改成您刚才设定好的数据文件夹名称, 如果也是使用的testdata, 那就不用修改了.
注意我这里使用的是文件的“相对路径”, ../表示从当前文件夹Octopus > python > pdf_parser退回到上一级Octopus > python, 然后再../退回一级到Octopus, 再进入/testdata.
把input_path修改成您刚才设定好的数据文件夹名称, 如果也是使用的testdata, 那就不用修改了.
注意我这里使用的是文件的“相对路径”, ../表示从当前文件夹Octopus > python > pdf_parser退回到上一级Octopus > python, 然后再../退回一级到Octopus, 再进入/testdata.
output_path可以和input_path一样.
fname, 如果您需要针对某一个特定文件进行处理, 就把文件名写上, 注意区分大小写, 要带有.pdf的后缀.
所有的名称都必须在双引号之内.
运行
1.
把页面一直拖动到最底部,
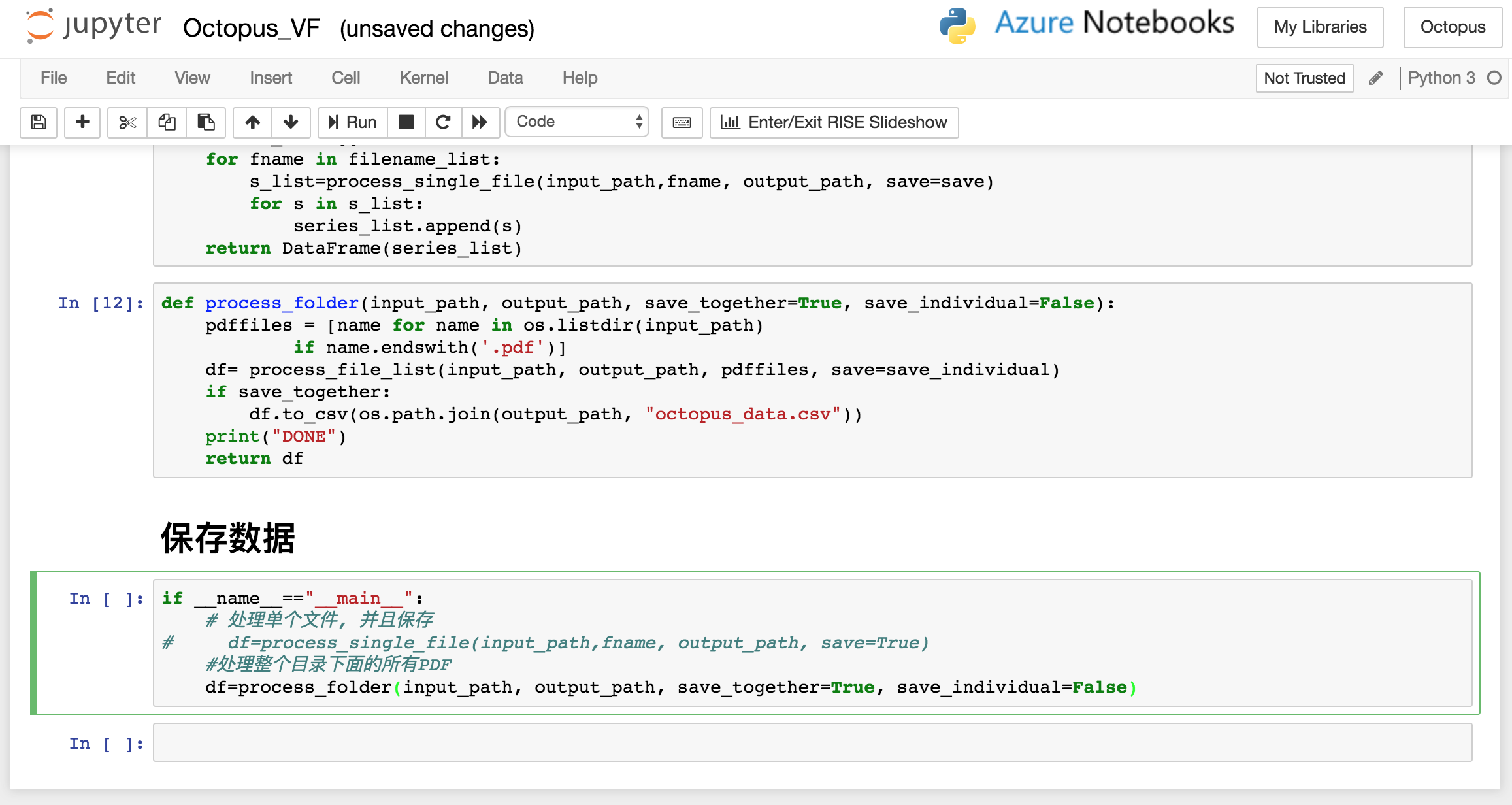
- 如果是想处理整个文件夹里所有的PDF文件, 就应该是图中这样的形式,
df=process_folder(input_path, output_path, save_together=True, save_individual=False)
- 如果想在处理文件夹的同时, 还想把每个PDF文件的数据单独提取成一个csv文件, 就把save_individual=True
2.
点击顶部菜单中的Kernel, 选择Restart & Run All
第一次运行的时候会比较慢, 因为用来处理PDF文件的工具包PDFminer.six需要安装. 会看到在import那一堆代码下面出现这样的安装过程, 第二次运行就不会有了.
 注意, 免费版本的azure notebook会在没有操作后1小时清空所有用户安装的软件包, 所以, 如果第二天再来, 仍然是“第一次”运行的状态. 但之前保存的数据文件不会被消除.
注意, 免费版本的azure notebook会在没有操作后1小时清空所有用户安装的软件包, 所以, 如果第二天再来, 仍然是“第一次”运行的状态. 但之前保存的数据文件不会被消除.
3.
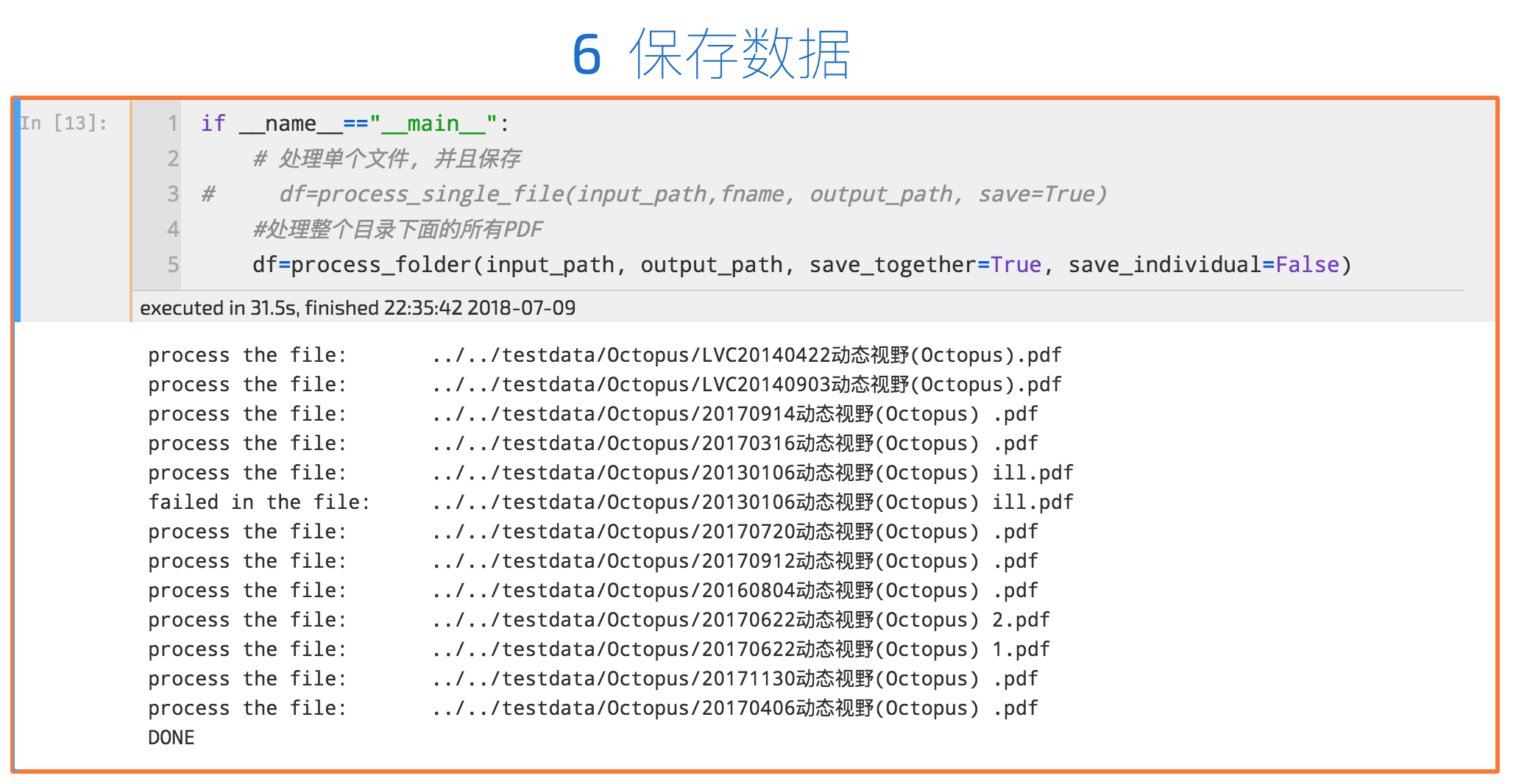
处理完成的文件会列出来, 如果有处理不了的PDF文件, 比如页面大小不是A4的, 或者是有密码限制了复制功能的, 都会标记出failed
取得结果
1.
再次回到Octopus > testdata 文件夹之下,
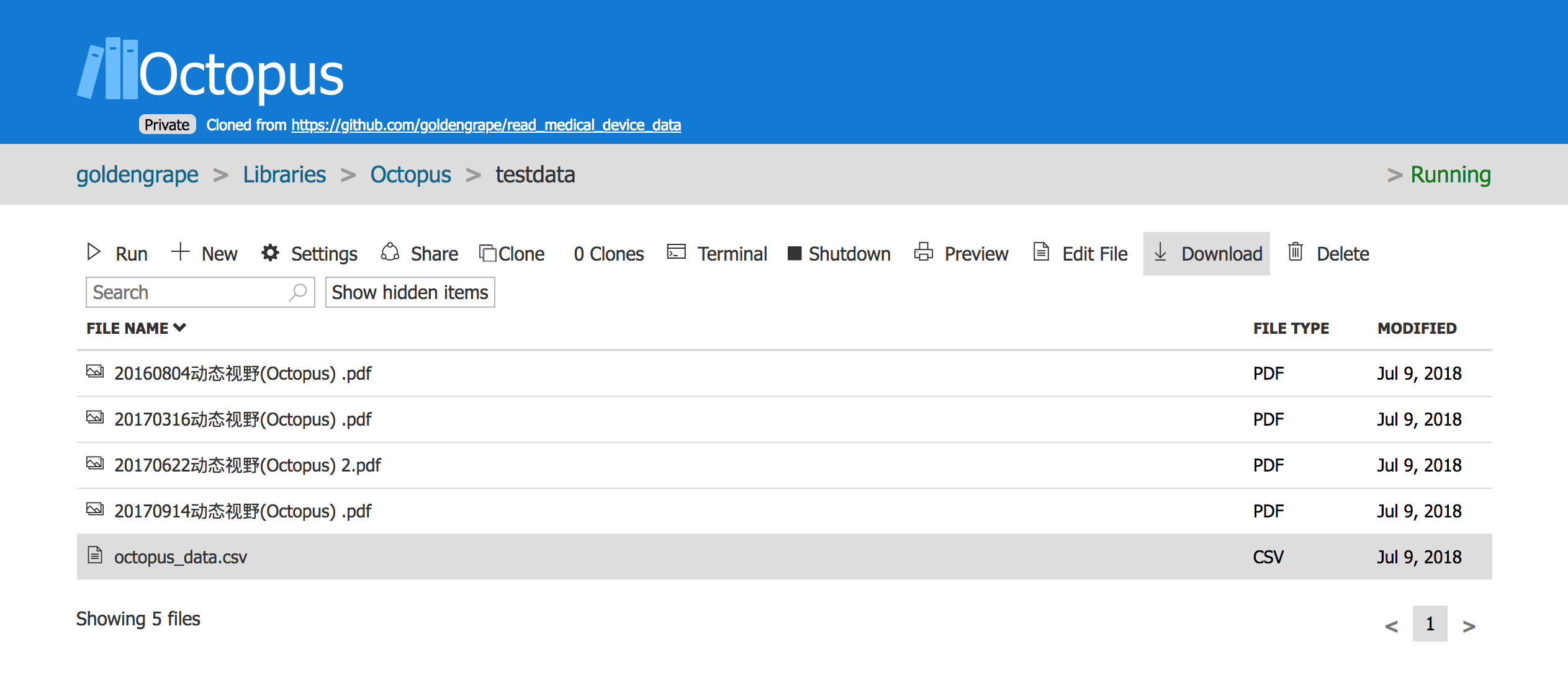 会看到octopus_data.csv文件已经生成了, 点击Download下载下来即可.
会看到octopus_data.csv文件已经生成了, 点击Download下载下来即可.
2.
excel中的数据, 每一行是一个文件中一页的数据, 因为经常病人是做双眼的检查, 但却放在同一个PDF文件里. 如何处理excel中的数据, 就是您自己的事情了.

其他
Octupus自家有数据处理软件, 叫EyeSuite, 还有人用R语言做好了一个开源的工具包OPI - Open Perimetry Initiative, 比我这个高级多了.
如果没有这些工具包, 那么用我这个小程序还有点意义, 我抓取了视野检查中的values, 也就是检查时的原始数据, 而不仅仅是MD之类统计好的数据.
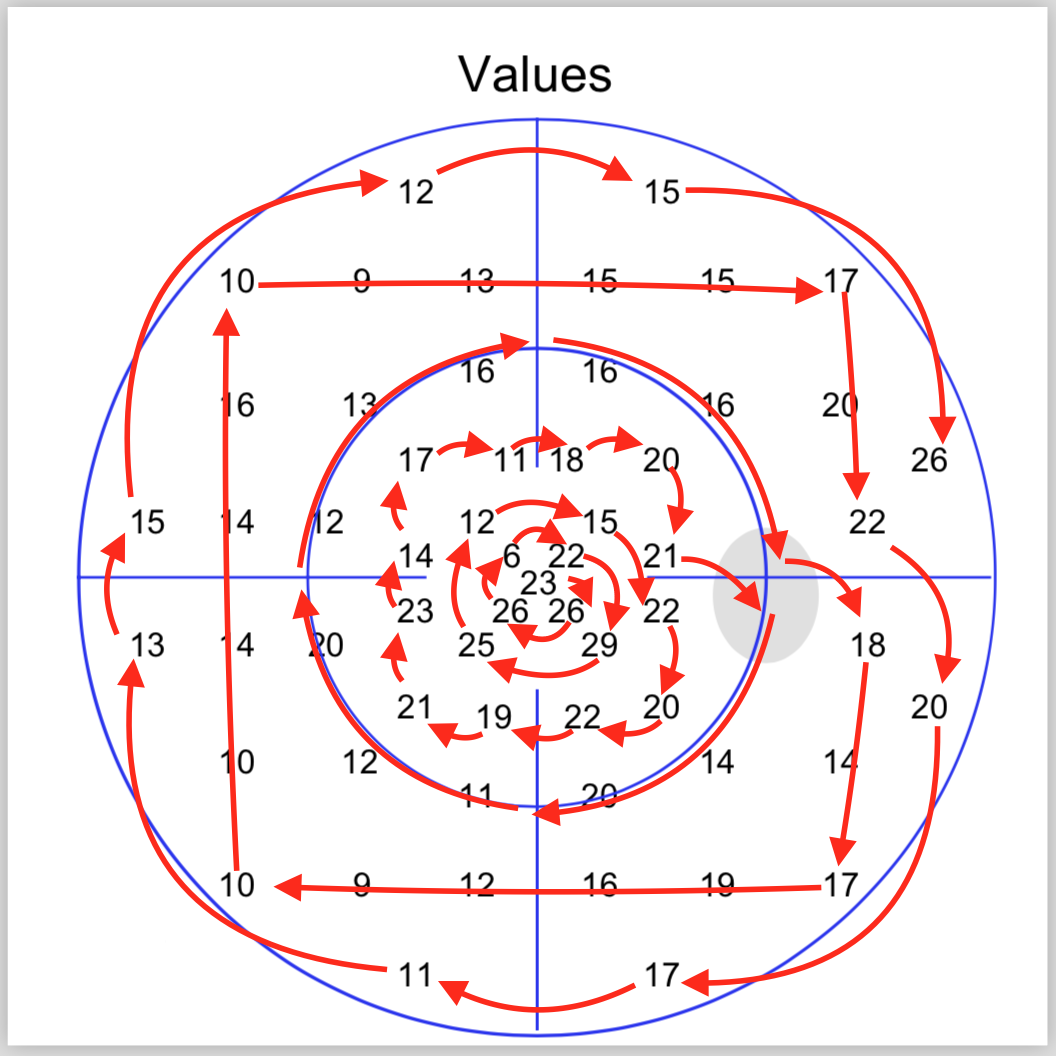
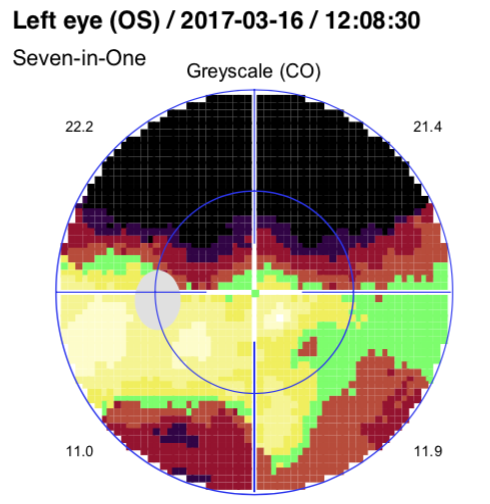
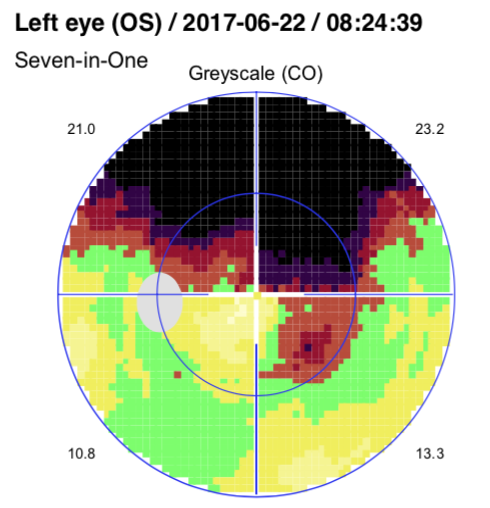
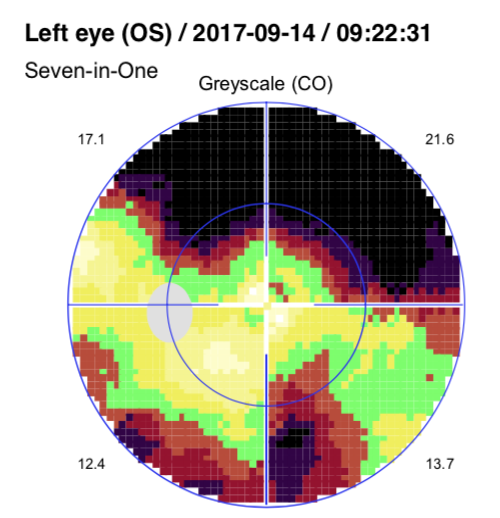
比如示例中的这个病人, 4次检查的MD分别是15.2/ 16.5/ 17/ 16.1, 虽然MD在增加, 但好像又有些波动. 那么视野是否在恶化呢?
MD是平均缺损, 只能反应整体平均的状态. 由于有了原始数据, 聚可以方便分析每个区域了. 比如很简单而不严格的, 我们可以对这4次检查的数据进行一次线性拟合, 得到的斜率如果是负数, 说明越来越差.
Excel的线性拟合使用LINEST函数.
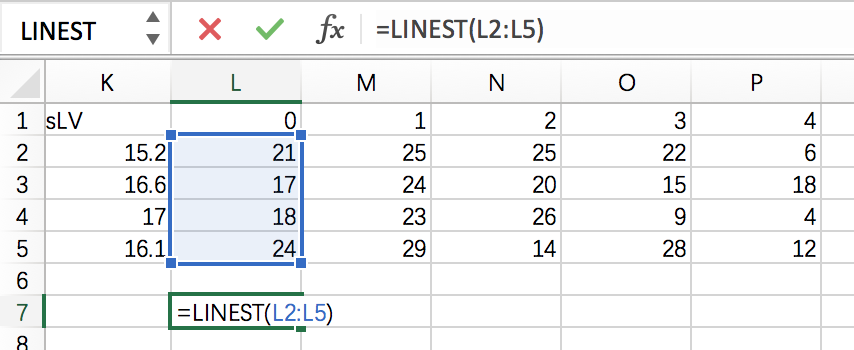 拖动复制, 对每列的value值都进行这样的操作.
拖动复制, 对每列的value值都进行这样的操作.
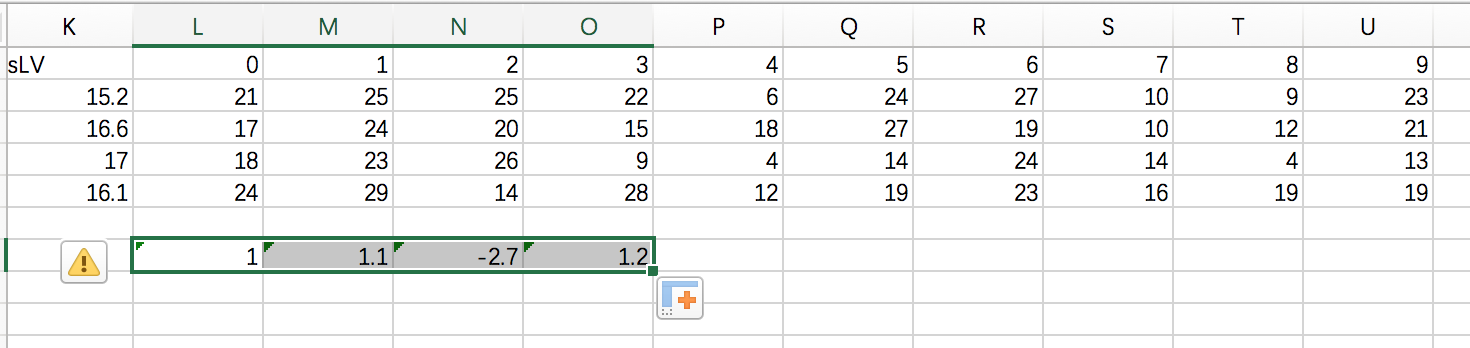
注意看这个区域恶化非常明显, 斜率已经分别是-2,-3,-1.8
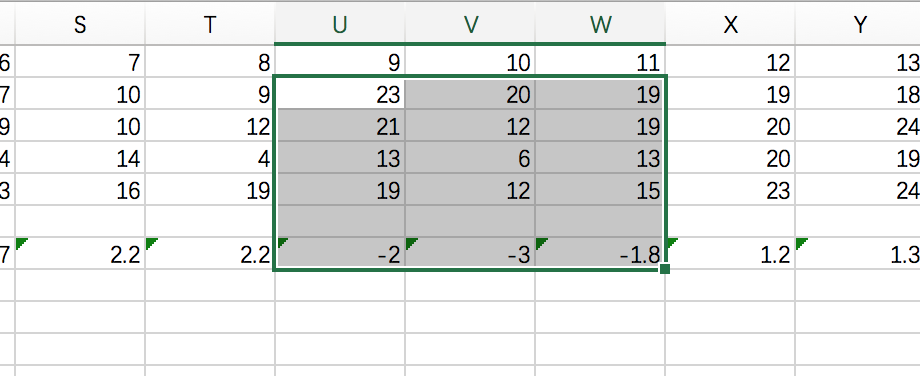
实际上这个区域对应的是中央视野附近.
随机森林
作为数据读取项目的一部分, octopus数据处理已经可以纳入到随机森林的机器学习功能之中, 详情请参考眼科数据随机森林
更新
这是一个业余程序员建立的开源项目, 我水平所限不要要求太高. 但我也还是会不断更新的, 修复bug或者添加新功能.
如果您已经导入到了azure notebooks里面, 也还是可以更新的. 更新代码的方法, 一种是可以新开一个library, 一种是在本library里更新. 如何新开一个之前已经讲过, 下面讲解一下如何更新.
- 点击Terminal 图标
将打开一个命令行界面.

- 输入如下命令:
cd library
进入到library文件夹里
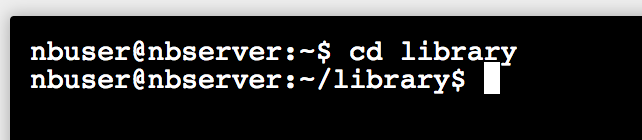
- 要更新代码, 需要先把之前您修改过的代码清除掉, 否则有冲突. 输入如下命令:
git checkout .
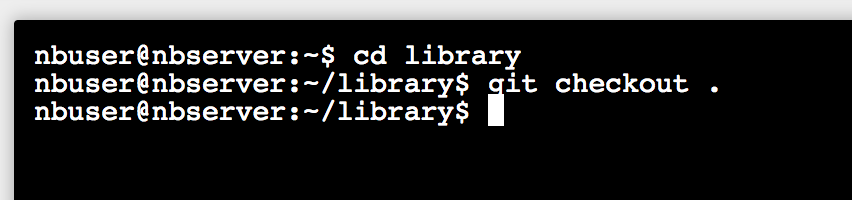
- 从github上把新代码“拉”到自己的library里. 输入如下命令:
git pull
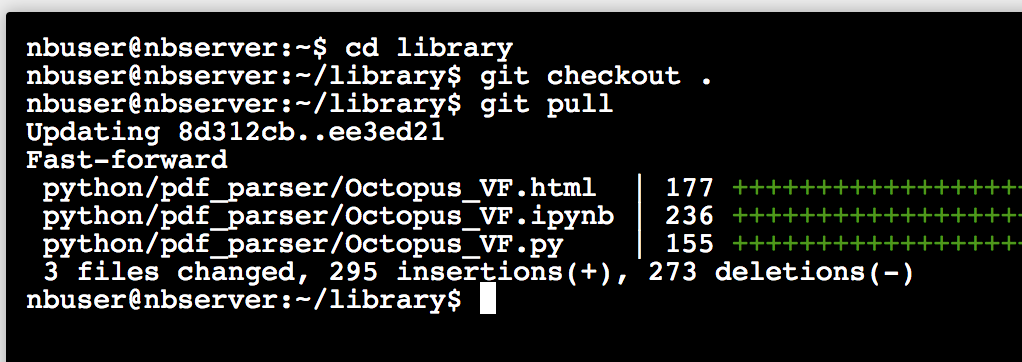
这样代码就更新完毕了, 关闭页面即可.
顺便, 推荐一下git, 如果您的电脑上存了很多“最终版”,“最终不变版本”,“最终最终版本”和“赌咒发誓这是最后一版”之类的文件名, 想必知道版本管理的重要性. git是一个很好的版本管理工具, 以后我会再详细讲解.